

1. 들어가며
Go는 goroutine(고루틴)이라는 독특한 방식으로 동시성을 관리합니다. 고루틴이라는 용어를 보면 가장 먼저 떠오르는 건 역시 코루틴이 아닐까 합니다. C# unity에서 다루는 코루틴이나, Kotlin에서도 자주 사용하는 coroutine 등 다른 언어에서도 흔히 볼 수 있는 기술입니다.
고루틴은 이들과 유사하면서도 차이점이 있습니다. 구체적인 차이점은 추후에 살펴보도록 하고 Go에서 동시성을 어떻게 관리하는지, 고루틴이란 무엇인지 살펴보도록 하겠습니다.
2. Go에서의 동시성 관리
우선 고루틴을 이해하기에 앞서 Go에서의 동시성이 OS 스레드와 CPU 코어와 함께 어떤 방식으로 실행되는지 그림과 함께 살펴보겠습니다.

- 운영 체제는 스레드가 물리적 프로세서에 대해 실행되도록 예약하고 Go 런타임은 고루틴이 논리적 프로세서에 대해 실행되도록 예약합니다.
- 각 논리적 프로세서는 개별적으로 단일 운영 체제 스레드에 바인딩됩니다. 버전 1.5부터는 기본적으로 사용 가능한 모든 물리적 프로세서에 논리적 프로세서를 할당합니다. 버전 1.5 이전에는 기본적으로 단일 논리적 프로세서만 할당했습니다.
- 이러한 논리적 프로세서는 생성된 모든 고루틴을 실행하는 데 사용됩니다.
- 단일 논리적 프로세서가 있어도 수십만 개의 고루틴을 빠른 성능으로 동시에 실행되도록 예약할 수 있습니다.
조금 더 구체적으로, 운영체제 스레드, 논리적 프로세서, 로컬 실행 큐와 함께 살펴보겠습니다.
- 고루틴이 생성되어 실행될 준비가 되면 스케줄러의 글로벌 실행 큐에 배치됩니다.
- 얼마 지나지 않아 논리적 프로세서에 할당되고 해당 논리적 프로세서의 로컬 실행 큐에 배치됩니다.
- 거기에서 고루틴은 실행을 위해 논리적 프로세서가 제공될 차례를 기다립니다.
- blocking을 일으키는 syscall이 일어날 경우 스레드와 고루틴은 논리적 프로세서에서 분리되고 syscall에서 반환될 때까지 계속 차단됩니다.
- 그리고 스케줄러는 새 스레드를 생성하여 논리적 프로세서에 연결합니다.
- 그런 다음 스케줄러는 실행을 위해 로컬 실행 대기열에서 다른 고루틴을 선택합니다.
- syscall이 반환되면 고루틴은 로컬 실행 대기열로 다시 배치되고 스레드는 나중에 사용할 수 있도록 따로 보관됩니다.
고루틴이 네트워크 I/O 호출을 해야 하는 경우 프로세스가 약간 다릅니다.
- 이 경우 고루틴은 논리적 프로세서에서 분리되어 런타임 통합 네트워크 폴러로 이동합니다.
- 폴러가 읽기 또는 쓰기 작업이 준비되었음을 나타내면 고루틴은 작업을 처리하기 위해 논리적 프로세서에 다시 할당됩니다.
- 생성할 수 있는 논리적 프로세서 수에 대한 제한은 스케줄러에 내장되어 있지 않습니다.
- 그러나 런타임은 기본적으로 각 프로그램의 스레드 수를 최대 10,000개로 제한합니다. 이 값은 패키지 SetMaxThreads에서 함수를 호출하여 변경할 수 있습니다 runtime/debug. 어떤 프로그램이 더 많은 스레드를 사용하려고 하면 프로그램이 충돌합니다.
3. Goroutine (고루틴)
고루틴(goroutine)이란, 프로그램에 있는 다른 고루틴과 관련하여 독립적으로 동시에 실행되는 함수입니다.
고루틴이 구체적으로 어떻게 실행되는지 그림과 함께 살펴보겠습니다.
- step1에서 스케줄러는 고루틴 B가 실행 큐에서 차례를 기다리는 동안 고루틴 A를 실행하기 시작합니다.
- 그런 다음 step2 에서 스케줄러는 갑자기 고루틴 A를 고루틴 B로 바꿉니다. 고루틴 A가 완료되지 않았으므로 실행 큐에 다시 배치됩니다.
- 그런 다음 3단계에서 고루틴 B가 작업을 완료하고 사라집니다. 이를 통해 고루틴 A가 다시 작업을 시작할 수 있습니다.
물론 처음에 실행한 고루틴 A가 빠르게 수행될 수 있다면 고루틴이 교체되는 것을 보지 못할 수도 있습니다. 여기서 중요한 점은 goroutine은 여타 스레드처럼 사용자가 관여하지 않아도 알아서 교체가 되어 다른 것이 실행될 수 있다는 점입니다! (이는 다른 코루틴과 중요한 차이점을 만들어냅니다.)
고루틴 논리 프로세서
Go 표준 라이브러리의 runtime 패키지에는 GOMAXPROCS를 통해 스케줄러가 사용할 논리 프로세서 수를 지정할 수 있습니다. 예를 들면
import "runtime"
// 사용 가능한 모든 코어에 대해 논리적 프로세서를 할당합니다.
runtime.GOMAXPROCS(runtime.NumCPU())
위 코드처럼 모든 코어를 사용 가능합니다.
각 코어에서 여러 스레드가 동시에 실행될 수 있으므로 병렬성을 확보할 수 있게 됩니다. 그렇다고 논리 프로세서를 늘린다고 꼭 성능이 좋아지는 것은 아니며 항상 본인 프로그램의 벤치마크에 기반해야 합니다.
Race condition
동시성 프로그래밍을 가장 어렵게 만드는 요소 중 하나는 역시 공유 자원 관리입니다. C에서는 mutex, semaphore를 활용하기도 하고, Java에서는 Reentrant Lock이나 Thread local을 통해 극복하기도 합니다.
혹시 Race condition이 낯선 분이라면 다음 글을 참조해주세요!
https://medium.com/trendyol-tech/race-conditions-in-golang-511314c0b85
Race conditions in Golang
Writing multi-threaded applications is a non-trivial job and requires planning before implementation. If you were using a single-threaded…
medium.com
Go에도 유사한 방식으로 Race condition을 해결할 수도 있고, Go만의 방식(Channel)으로 해결할 수도 있습니다. 그 전에 go에서 제공하는 경쟁 상태를 감지할 수 있는 도구에 대해 먼저 알아보도록 하겠습니다.
1) 경쟁 상태 감지 도구 - go build - race
Go에는 코드에서 경쟁 조건을 감지할 수 있는 특수 도구가 있습니다.
go build를 할 때 -race 플래그를 붙이면 어떤 고루틴이 경쟁 상태를 만드는지 보여줍니다.
다만 이 옵션은 https://go.dev/doc/articles/race_detector 글에서 볼 수 있듯이 일 반적인 프로그램의 경우 메모리 사용량은 5~10배, 실행 시간은 2~20배 증가할 수 있습니다. 즉 테스트 용도로만 사용하는 것이 적절합니다.
그리고 https://stackoverflow.com/questions/57298304/why-is-the-race-detector-not-detecting-this-race-condition와 같은 상황, 즉 논리적인 경쟁 상태(프로그래머가 의도한 대로 동작하지 않음. 위 코드는 실수에 가까워 보입니다.)이지만 실제로 경쟁 상태는 아닌 상황은 잡지 못하기도 합니다. 사실 위 링크의 코드는 데이터를 동시에 "접근"하는 일은 없으므로 race condition은 아니라고도 볼 수 있겠습니다만 이러한 실수까지는 잡아주지 않는다는 걸 알아두면 좋을 것 같습니다.
그럼 go에서 어떻게 경쟁 상태를 해결할 수 있는지 하나씩 살펴보도록 하겠습니다.
2) 원자 함수
원자 함수는 정수나 포인터에 대한 액세스를 동기화하기 위한 저수준 잠금 매커니즘을 제공합니다.
atomic.AddInt64(&counter, 1)
예를 들어 위와 같이 원자적 연산 함수를 사용한다면 해당 변수에 대한 동기화가 가능합니다.
3) 뮤텍스
c언어에서 많이 익숙하지 않을까 하는 lock입니다. 별도로 설명을 하지는 않겠습니다.
mutex sync.Mutex
mutex.Lock()
mutex.Unlock()
여타 언어처럼 Lock과 UnLock 사이에서 임계 구역 진입을 통제합니다.
4) 채널 (Channel)
원자 함수나 뮤텍스는 사실 다른 언어에도 다 있는 것입니다. Go가 동시성 프로그램에 특화되어 있다고 하기엔 저 기능만으로는 부족해보입니다. Go에서는 Channel을 통해 공유해야 하는 리소스를 보내고 받을 때 동기화할 수 있습니다.
채널이란 동시에 실행되는 고루틴들을 연결해주는 일종의 파이프(pipe)입니다.
채널을 선언할 때 공유될 데이터 유형을 지정합니다. 그리고 채널에 문자열을 전송할 수 있습니다.
// 정수의 버퍼링되지 않은 채널.
unbuffered := make(chan int)
// 문자열의 버퍼링된 채널.
buffered := make(chan string, 10)
// 채널을 통해 문자열을 전송합니다.
buffered <- "Gopher"
// 다른 고루틴에서 전송한 값을 받기 위해선
// 채널에서 문자열을 수신합니다.
value := <-buffered
채널에는 중요한 두 가지 구문이 있습니다. <- 와 -> 입니다.
채널에 데이터를 보내려면 channel <-
채널에서 데이터를 받으려면 <- channel
이렇게 사용할 수 있습니다.
고루틴 안에 생성된 채널은 해당 채널에 데이터가 전달될 때 까지 데이터를 받는 채널은 대기하게 됩니다. 이러한 동시적인 특징으로 인해 채널은 고루틴의 데드락을 방지하며 함수의 흐름을 제어할 수 있습니다.
race condition이란 여러 스레드가 공유 자원에 접근하면서 발생하게 됩니다. 고루틴 채널은 이런 접근 흐름을 개발자가 명시적으로 제어함으로써 race condition을 제거할 수 있습니다. 즉 이벤트에 따라 Critical Section을 순차적으로 접근하는 방법론입니다.
채널을 설명하기에 앞서 말씀드리자면 기존의 해결 방법인 mutex를 배제하지는 말라는 점을 말씀드리고 싶습니다. Go 공식 문서에서도 비슷한 이야기를 하고 있습니다. 다음 문서는 mutex와 channel 중 어떤 것을 고르는 것이 좋을지 조언하는 go 공식 문서입니다 :)https://go.dev/wiki/MutexOrChannel
Go Wiki: Use a sync.Mutex or a channel? - The Go Programming Language
Go Wiki: Use a sync.Mutex or a channel? One of Go’s mottos is “Share memory by communicating, don’t communicate by sharing memory.” That said, Go does provide traditional locking mechanisms in the sync package. Most locking issues can be solved usi
go.dev
A common Go newbie mistake is to over-use channels and goroutines just because it’s possible, and/or because it’s fun. Don’t be afraid to use a sync.Mutex if that fits your problem best. Go is pragmatic in letting you use the tools that solve your problem best and not forcing you into one style of code.
또한 http://www.dogfootlife.com/archives/452 자료를 보면 Mutex가 속도가 빠르다는 벤치마크가 있기도 하고, Channel이 할 수 있는 일은 Mutex로도 구현할 수 있습니다.
하지만.
- 개발자는 컴퓨터가 아니기 때문에 Mutex 만으로는 완벽하지 않습니다.
- 복잡한 Mutex 는 메모리 누수를 일으키고, 메모리 누수는 데드락을 일으킵니다.
- Mutex 가 아닌 채널 중심으로 코딩을 하다보면 Goroutine Leak 을 찾기 편해지고, 자원회수를 하기 쉽습니다.
- 이름도 정할 수 없는 A 라는 메모리를 Lock / UnLock 하면서 접근하는 것보다는, 특정 Event 에 따라 순차 접근하는 것이 개발자에게 보기 편하다는 장점이 있습니다.
-> Golang에서 제공하는 Channel이 막강한 기능임을 명심하면서 Mutex를 배제하지 않는 편이 좋겠습니다.
그럼 Channel을 통해 데이터를 기다리는 예시를 코드를 통해 살펴보겠습니다.
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
c<-3
fmt.Println("test")
}()
}
/*
실행 결과 :
*/
위의 코드를 실행하면 test라는 문구가 콘솔에 찍혀야 하지만 아무것도 나오지 않습니다.
그 이유는, 채널 데이터를 수신할 대 까지, 대기 상태가 되었기에 실행이 멈춘 것입니다.
데이터 수신 부분을 추가하면 위의 코드는 정상 작동하게 됩니다. 해당 코드를 살펴보겠습니다.
package main
import "fmt"
func main() {
c := make(chan int) // 채널 생성
go func() {
c<-3 // 데이터 전송
}()
fmt.Println(<-c) // 데이터 수신 후, 값 출력
fmt.Println(c) // 채널의 주소값. 실행 결과는 매번 달라진다.
}
/*
실행 결과 :
3
0xc000080060
*/
c라는 채널을 생성한 후, 고루틴 익명함수 안에서 데이터를 전송한 후, main() 함수에서 c채널의 데이터 값을 출력합니다.
채널의 종류
// 정수의 버퍼링되지 않은 채널.
unbuffered := make(chan int)
// 문자열의 버퍼링된 채널.
buffered := make(chan string, 10)
// 채널을 통해 문자열을 전송합니다.
buffered <- "Gopher"
// 다른 고루틴에서 전송한 값을 받기 위해선
// 채널에서 문자열을 수신합니다.
value := <-buffered처음으로 돌아가 위 코드의 주석을 보면 버퍼링되지 않은 채널과 버퍼링된 채널 두 가지가 있는 것을 알 수 있습니다. 이 두가지는 동작이 다소 다릅니다.
a) 버퍼링 되지 않은 채널
버퍼링 되지 않은 채널은 수신되기 전에 어떤 값도 보관할 수 있는 용량이 없는 채널입니다.
- 이러한 유형의 채널은 모든 송신 또는 수신 작업이 완료되기 전에 송신 및 수신 고루틴이 모두 같은 순간에 준비되어야 합니다.
- 두 고루틴이 같은 순간에 준비되지 않으면 채널은 해당 송신 또는 수신 작업을 수행하는 고루틴을 먼저 기다리게 합니다.
- 동기화는 채널에서 송신과 수신 간의 상호 작용에 내재되어 있습니다. 하나는 다른 하나 없이는 발생할 수 없습니다.
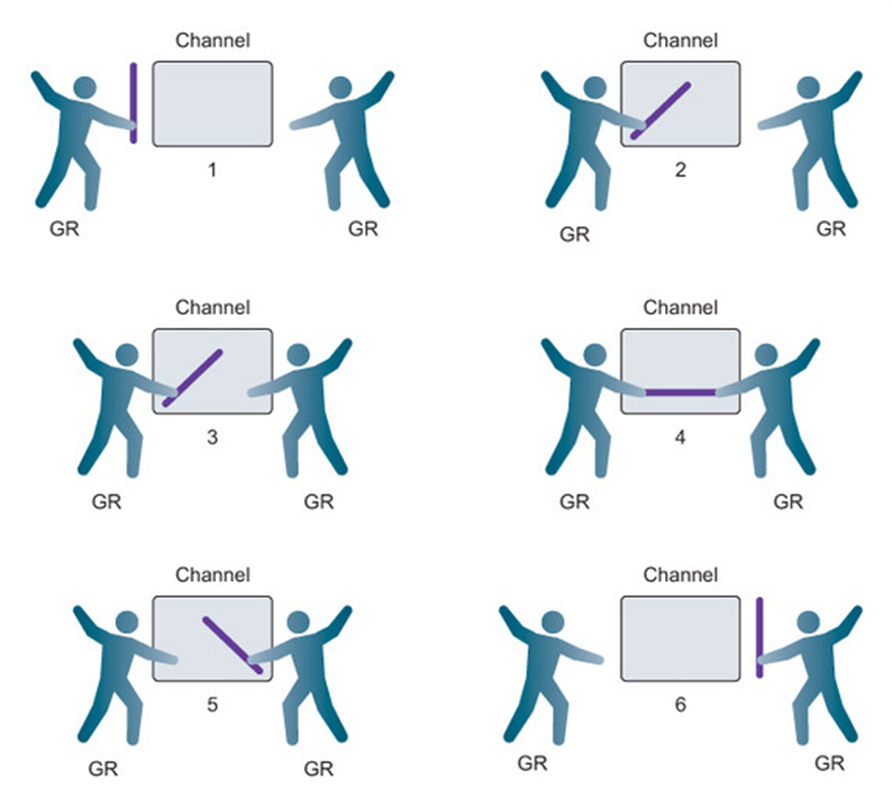
- 1단계에서 두 개의 고루틴이 채널에 접근하지만 아직 둘 다 전송이나 수신을 실행하지 않았습니다.
- 2단계에서 왼쪽의 고루틴이 채널에 손을 넣어 채널에서 전송을 시뮬레이션합니다. 이 시점에서 해당 고루틴은 교환이 완료될 때까지 채널에 잠겨 있습니다.
- 3단계에서 오른쪽의 고루틴이 채널에 손을 넣어 채널에서 수신을 시뮬레이션합니다. 해당 고루틴은 이제 교환이 완료될 때까지 채널에 잠겨 있습니다.
- 4단계와 5단계에서 교환이 이루어지고
- 마지막으로 6단계에서 두 고루틴 모두 손을 떼서 잠금이 해제된 것을 시뮬레이션합니다. 이제 둘 다 즐거운 길을 갈 수 있습니다!
b) 버퍼링 된 채널
버퍼링된 채널은 수신 되기 전에 하나 이상의 값을 보관할 수 있는 용량이 있는 채널입니다.
- 이러한 유형의 채널은 고루틴이 송신 및 수신을 수행하기 위해 동시에 준비되도록 강제하지 않습니다.
- 송신 또는 수신이 차단되는 경우에도 다른 조건이 있습니다.
- 수신은 채널에 수신할 값이 없는 경우에만 차단됩니다.
- 송신은 전송되는 값을 저장할 사용 가능한 버퍼가 없는 경우에만 차단됩니다.
- 이로 인해 버퍼링되지 않은 채널과 버퍼링된 채널 간의 한 가지 큰 차이점이 생깁니다.
- 버퍼링되지 않은 채널은 송신 및 수신이 발생하는 순간에 두 고루틴 간의 교환이 수행되도록 보장합니다.
- 버퍼링된 채널은 이러한 보장이 없습니다.
- 버퍼의 크기를 정하게 되면, 해당 채널에 할당된 버퍼의 크기가 넘지 않도록 주의해야 합니다. 그렇지 않으면 오류가 발생합니다.
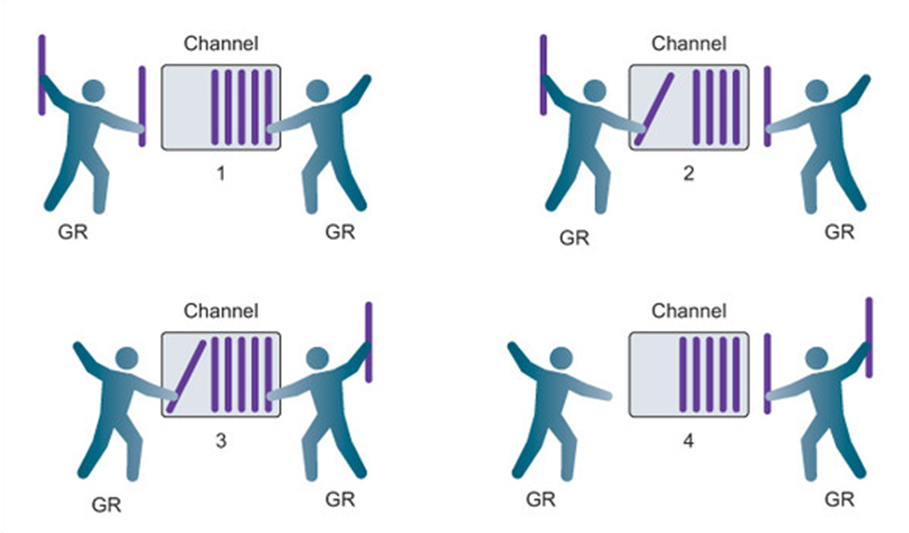
- 1단계에서 오른쪽의 고루틴은 채널에서 값을 수신하는 과정에 있습니다.
- 2단계에서 동일한 고루틴은 왼쪽의 고루틴이 채널에 새 값을 보내는 것과는 독립적으로 수신을 완료할 수 있습니다.
- 3단계에서 왼쪽의 고루틴은 채널에 새 값을 전송하는 반면 오른쪽의 고루틴은 다른 값을 수신합니다.
- 3단계의 이 두 작업은 서로 동기화되지 않거나 차단되지 않습니다.
- 마지막으로 4단계에서 모든 전송 및 수신이 완료되고 여러 값과 더 많은 공간이 있는 채널이 있습니다.
Select - 채널 다중 연산
채널을 통해 다중 연산을 하는 경우 이를 손쉽게 사용할 수 있는 셀렉트라는 분기문을 제공합니다. 이를 통해 원하는 채널에 값이 들어왔을 때만 해당 분기문을 실행하기 때문에 다중 채널을 통한 연산시 동기화 연산으로 확장시킬 수 있습니다.
package main
import (
f "fmt"
"time"
)
func main() {
f.Println("select")
c1 := make(chan string)
c2 := make(chan string)
go func() { // 익명함수를 통한 고루틴 생성
time.Sleep(time.Second * 1) // 1초간 대기
c1 <- "one" // c1 채널에 string 값 one을 전송
}()
go func() {
time.Sleep(time.Second * 2)
c2 <- "two"
}()
for i := 0; i < 2; i++ {
select { // 해당 select 분기문 안에 있는 채널에 값이 들어왔을 때 case 내용을 실행한다.
case msg1 := <-c1:
f.Println("received", msg1)
case msg2 := <-c2:
f.Println("received", msg2)
}
}
}
select 분기문도 default 케이스를 지정할 수 있으며 case에 지정된 채널에 값이 들어오지 않았을 때 즉시 실행됩니다. 단, default에 적절한 처리를 하지 않으면 CPU 코어를 모두 점유하므로 주의해야 합니다.
고루틴과 코루틴의 차이점
여기까지 왔다면 기존의 다른 언어의 코루틴에 익숙한 분이라면 고루틴과 코루틴이 무엇이 다른지 궁금할 수 있다고 생각합니다. (적어도 저는 그랬습니다...!)
다음의 참고 자료를 활용하여 간략하게 정리해보았습니다.
Which of coroutines (goroutines and kotlin coroutines) are faster?
Kotlin corutines is sugar for finite state machine and some task runner (for example, default ForkJoinPool). https://github.com/Kotlin/kotlin-coroutines/blob/master/kotlin-coroutines-informal.md#
stackoverflow.com
https://stackoverflow.com/questions/18058164/is-a-go-goroutine-a-coroutine
Is a Go goroutine a coroutine?
In the Google I/O 2012 presentation Go Concurrency Patterns, Rob Pike mentions that several goroutines can live in one thread. Does this imply that they are implemented as coroutines? If not, how t...
stackoverflow.com
코루틴은 다른 코루틴으로 제어를 이전하기 위한 명시적 수단을 지원하는 것을 의미합니다. 즉, 프로그래머는 코루틴이 실행을 중단하고 다른 코루틴으로 제어를 넘길 때(호출하거나 반환/종료(일반적으로 양보라고 함))를 결정할 때 코루틴을 프로그래밍합니다.
Go의 "고루틴"은 또 다른 것입니다. 고루틴이 I/O 완료, 채널 전송 등과 같은 어떤 (외부) 리소스에서 sleep 하려고 할 때 발생하는 특정 불확정 지점 에서 암묵적으로 제어권을 넘깁니다 . 채널을 통해 상태를 공유하는 것과 결합된 이 접근 방식은 프로그래머가 프로그램 로직을 일련의 순차적인 경량 프로세스로 작성할 수 있게 하여 코루틴 및 이벤트 기반 접근 방식 모두에서 공통적으로 발생하는 스파게티 코드 문제를 제거합니다.
고루틴은 동시성을 사용하기 쉽게 만드는 요소입니다. 얼마 전부터 있었던 아이디어는 독립적으로 실행되는 함수(코루틴)를 스레드 집합에 멀티플렉스하는 것입니다. 코루틴이 차단 시스템 호출을 호출하는 것과 같이 차단되면 런타임은 동일한 운영 체제 스레드의 다른 코루틴을 다른 실행 가능한 스레드로 자동으로 이동하여 차단되지 않도록 합니다. 프로그래머는 이런 것을 전혀 보지 못하는데, 이것이 요점입니다. 고루틴이라고 부르는 결과는 매우 저렴할 수 있습니다. 스택의 메모리를 넘어서는 오버헤드가 거의 없으며, 이는 몇 킬로바이트에 불과합니다.
- 코루틴은 병렬성 없이 동시성을 제공합니다. 즉, 한 코루틴이 실행 중일 때, 재개하거나 양보한 코루틴은 실행 중이 아닙니다. 코루틴은 프로그램 구조화를 위한 동시성을 원하지만 병렬성을 원하지 않는 프로그램을 작성하는 데 유용한 구성 요소입니다.
- 코루틴은 한 번에 하나씩 실행되고 프로그램의 특정 지점에서만 전환되므로 코루틴은 경쟁 없이 서로 데이터를 공유할 수 있습니다. 명시적 전환은 동기화 지점 역할을 하여 happens-before 에지를 만듭니다.
- 스케줄링이 명시적(선점 없이)이고 운영 체제 없이 완전히 수행되기 때문에 코루틴 스위치는 약 10나노초가 걸리며 보통 그보다 더 짧습니다. 시작과 종료도 스레드보다 훨씬 저렴합니다.
- 고루틴 스위치는 Go 런타임이 일부 스케줄링 작업을 담당하기 때문에 수백 나노초에 더 가깝습니다. 그러나 고루틴은 여전히 스레드의 완전한 병렬 처리와 선점을 제공합니다.
고루틴 vs 코루틴
차이점
- 코루틴은 특정 지점에서 실행을 양보하고 재개하는 데 초점을 맞춰 동시성은 가능하지만 병렬성은 가능하지 않습니다. 이는 동시적 작업 처리보다 제어된 실행 흐름이 더 중요한 특정 프로그래밍 시나리오에서 유용합니다.
- Go의 고루틴은 완전한 병렬성과 선점을 제공하며, 런타임은 일부 스케줄링 작업을 처리합니다. 여러 제어 흐름을 동시에 병렬로 실행할 수 있습니다.
조금 재밌는 글로 Kotlin에 있는 coroutine과 go에 있는 goroutine이 각각 어떤 상황에 적절한 지 비교한 글도 있었습니다.
각각 적합한 상황
- Kotlin 코루틴은 Go 고루틴보다 인스턴스당 메모리가 적게 필요합니다. Kotlin의 간단한 코루틴은 힙 메모리에서 수십 바이트만 차지하는 반면, Go 고루틴은 4KiB의 스택 공간으로 시작합니다. 즉, 수백만 개의 코루틴을 계획하고 있다면 Kotlin의 코루틴이 Go보다 유리할 수 있습니다. 또한 Kotlin 코루틴은 생성기 및 지연 시퀀스와 같은 매우 수명이 짧고 작은 작업에 더 적합합니다.
- Kotlin 코루틴은 모든 스택 깊이로 갈 수 있지만, 일시 중단 함수의 각 호출은 스택에 대한 힙의 객체를 할당합니다. Kotlin 코루틴의 호출 스택은 현재 힙 객체의 연결 리스트로 구현됩니다. 반면, Go의 고루틴은 선형 스택 공간을 사용합니다. 이는 Go에서 딥 스택에서의 일시 중단을 더 효율적으로 만듭니다. 따라서 작성하는 코드가 스택의 아주 깊은 곳에서 일시 중단하는 경우 고루틴이 더 효율적일 수 있습니다.
- Go 런타임은 물리적 OS 스레드에서 고루틴 실행을 스케줄링하는 것을 완전히 제어합니다. 이 접근 방식의 장점은 모든 것을 생각할 필요가 없다는 것입니다. Kotlin 코루틴을 사용하면 코루틴의 실행 환경을 세부적으로 제어할 수 있습니다. 이는 오류가 발생하기 쉽습니다(예: 서로 다른 스레드 풀을 너무 많이 만들어서 스레드 간의 컨텍스트 전환에 CPU 시간을 낭비할 수 있음). 그러나 애플리케이션의 스레드 할당 및 컨텍스트 전환을 세부적으로 조정할 수 있습니다. 예를 들어, Kotlin에서는 적절한 코드를 작성하기만 하면 전체 애플리케이션 또는 해당 코드의 하위 집합을 단일 OS 스레드(또는 스레드 풀)에서 실행하여 OS 스레드 간의 컨텍스트 전환을 완전히 피할 수 있습니다.
'programming language > Go' 카테고리의 다른 글
| Go 파헤치기 - 타입 시스템, 인터페이스, 타입 임베딩 (1) | 2024.08.13 |
|---|---|
| Go 파헤치기 - Arrays, Slices, Maps (0) | 2024.08.12 |
| Go 파헤치기 - 들어가며, Import and Tooling (0) | 2024.08.12 |
| Go의 기본 문법과 Receiver (1) | 2023.12.23 |