

1. 들어가며
원래는 다음 글에 InnoDB의 락을 정리했었습니다.
https://rawshrimpsushi.tistory.com/68
그런데 다른 글 주제와 함께 쓰다보니 원하는 만큼 정리하지 못하고 요약하여 정리하는 문제가 있었습니다. 당연한 얘기겠지만 MySQL의 락은 하나의 글로 정리하기 힘들 정도로 큰 내용이다보니, 위 글에서 정리한 내용과 함께 따로 글로 정리하고자 합니다.
기본적인 락 개념과 MVCC에 대한 내용은 다음 글을 참조해주세요!
https://rawshrimpsushi.tistory.com/38
MySQL 아키텍쳐
본 내용은 real MySQL 책을 참조하여 쓰여졌습니다! 1. 기본 아키텍쳐 크게 MySQL 엔진과 스토리지 엔진으로 구분할 수 있습니다. MySQL 엔진: 1) 커넥션 핸들러: 클라이언트의 접속 및 쿼리 요
rawshrimpsushi.tistory.com
https://rawshrimpsushi.tistory.com/39
트랜잭션과 락
본 내용은 real MySQL 책을 참조하여 쓰여졌습니다! 1. 트랜잭션 트랜잭션의 기본 개념에 대해서는 다음 블로그를 참조해주세요! 이 글은 트랜잭션에 대해 이미 이해하고 있음을 가정하고
rawshrimpsushi.tistory.com
2. InnoDB의 MVCC와 락 모델
InnoDB에서는 기본적으로 MVCC를 통해 하나의 레코드에 대해 여러 개의 버전으로 관리합니다. 이를 통해 잠금 없는 일관된 읽기를 보장하기 위함인데요. 우선 MVCC가 InnoDB에서 어떻게 구현되는지 간단히 살펴보겠습니다.
InnoDB는 undo tablespace를 활용해서 데이터의 버전을 관리합니다.
InnoDB는 내부적으로 다음 정보를 데이터(row)와 함께 저장합니다.
- DB_TRX_ID: 데이터를 insert 또는 update 한 가장 최근의 transaction id
- DB_ROLL_PTR(roll pointer): 해당 데이터에 update가 수행되면 undo tablespace에 이전 버전의 데이터가 기록됩니다. DB_ROLL_PTR는 이전 버전의 데이터를 가리킵니다.
- DB_ROW_ID: 새로운 데이터(row)가 insert 될 때마다 1씩 증가하는 값입니다.
InnoDB의 undo log는 insert undo log와 update undo log로 나뉩니다.
- Insert undo log: Insert transaction이 rollback 되는 경우에만 필요합니다. 트랜잭션이 커밋되는 순간 해당 undo log는 삭제됩니다.
- Update undo log: Consistent read를 위해서 사용됩니다. 트랜잭션이 이전 버전의 데이터를 읽어야 하는 경우 활용합니다. 만약 update undo log에 기록된 로그 중 트랜잭션에 의해 참조되지 않는다면 삭제될 수 있습니다.
3. InnoDB의 락 종류
InnoDB에는
- 기본적으로 row level locking
- 전통적인 two phase locking
을 지원합니다.

레코드 락
일반적으로 레코드 락이라고 하면 테이블 레코드를 잠근다고 생각합니다. 하지만 MySQL에서의 레코드 락은 테이블의 레코드가 아닌 인덱스의 레코드를 잠근다는 중요한 차이가 있습니다.
참고로 여기서 락이 걸리는 인덱스는 클러스터 인덱스(PK) 및 논클러스터 인덱스(세컨더리 인덱스) 모두를 포함합니다. 만약 PK가 없는 테이블이라면 내부적으로 자동 생성된 PK를 이용해 설정합니다.
예를 들어 employees라는 테이블이 있고 first_name과 last_name column이 있다고 하겠습니다. 그 중 first_name에만 인덱스가 되어 있다고 해볼까요?
또한 first_name = ‘Georgi’은 100건
first_name = ‘Georgi’ AND last_name = ‘Klassen’은 1건만 존재하는 상황이 있다고 해봅시다.
그럴 경우
UPDATE employees SET hire_date = NOW() WHERE first_name = ‘Georgi’ AND last_name = ‘Klassen’;라는 update 쿼리가 있고 해당 레코드가 1건이라면 어떻게 될까요? 놀랍게도 last_name에는 인덱스가 없기 때문에 first_name = ‘Georgi’에 해당되는 100건의 레코드에 모두 락이 걸리게 됩니다.
즉 Update를 위한 적절한 인덱스가 없다면 동시성이 엄청나게 떨어지게 됩니다.
갭락
레코드 락이 테이블이 아닌 인덱스에 걸린다는 점을 포함하여, MySQL의 락에는 특별한 것이 하나 더 있습니다. 바로 갭 락입니다. 갭 락(Gap Lock)은 레코드가 아닌 레코드와 레코드 사이의 간격을 잠금으로써 레코드의 생성, 수정 및 삭제를 제어합니다..
예를 들어 현재 성이 S로 시작하는 레코드가 Smith, Samuel 2개가 있다고 해볼까요? 그리고 언제든지 다른 데이터들 ex) Sam, Son이 추가될 수 있습니다. 갭 락은 이렇듯 인덱스 범위 조건 중에서 실제 레코드를 제외하고, 데이터가 추가될 수 있는 범위에 걸리게 됩니다.
InnoDB 인덱스 데이터 구조 에서 새 값을 삽입할 수 있는 위치 입니다. SELECT ... FOR UPDATE와 같은 명령문으로 행 집합을 잠그면 인덱스의 실제 값뿐만 아니라 갭에도 적용되는 잠금을 생성할 수 있습니다. 예를 들어, 업데이트를 위해 10보다 큰 모든 값을 선택하면 갭 잠금으로 인해 다른 트랜잭션이 10보다 큰 새 값을 삽입하지 못합니다. supremum 레코드 와 infimum 레코드는 현재 모든 인덱스 값보다 크거나 작은 모든 값을 포함하는 갭을 나타냅니다.
인덱스 레코드 사이의 갭 에 대한 Lock 또는 첫 번째 또는 마지막 인덱스 레코드 앞의 갭에 대한 잠금입니다. 예를 들어, 범위에 있는 모든 기존 값 사이의 갭이 잠겨 있기 때문에 열에 이미 그러한 값이 있든 없든 다른 트랜잭션이 열에 값 15를 삽입하지 못하도록 합니다 . Record Lock 및 Next Key Lock 과 대조됩니다 .
갭 잠금은 성능과 동시성 간의 균형의 일부이며 일부 트랜잭션 격리 수준 에서는 사용되고 다른 수준에서는 사용되지 않습니다.
다음 자료에 더 자세히 아주 잘 정리되어 있으니 참조해보세요!
https://medium.com/daangn/mysql-gap-lock-다시보기-7f47ea3f68bc
gap lock의 락 수준은 다음과 같습니다.
- Shared Gap Lock = Exclusive Gap Lock
- Next Key Lock = Record Lock + Gap Lock
테이블 record가 적을 수록 GAP LOCK의 영향력은 강한데, 이는 Pseudo Infimum Record부터 Pseudo Supremum Record까지 잠그는 일이 벌어지기 때문입니다.
Insert를 위한 Gap lock도 존재합니다: INSERT Intention Gap Lock은, INSERT 문장들은 Duplicate Key 에러만 아니면 동시에 실행될 수 있도록 구현하기 위함입니다.
공식 문서의 동시성 , 갭 잠금 , 인덱스 , 최소 레코드 , 격리 수준 , 최대 레코드 도 참조해보세요!!
넥스트 키 락
넥스트 키 락은 레코드 락과 갭 락이 합쳐진 락입니다. 앞서 보았던 갭 락도 단독으로 사용된다기보단 이 넥스트 키 락의 일부로 사용됩니다.
이런 락은 bin_log에 기록되는 쿼리가 레플리카에서 실행될 때 원본에서의 결과와 동일한 결과를 만들기 위해 주로 사용된다고 합니다. 그런데 이 갭 락으로 데드락이 발생할 수도 있어 바이너리 로그 포맷을 ROW로 바꾸면 도움이 됩니다.
자동 증가 락
자동 증가 락은 다중 클라이언트가 동시에 동일한 AUTO_INCREMENT 값을 가져오지 않도록 보장하는 락입니다.
해당 락은 INSERT와 REPLACE와 같이 새로운 레코드를 저장하는 쿼리에서만 사용됩니다. 또한 트랜잭션과 관계없이 INSERT나 REPLACE 문장에서 AUTO_INCREMENT 값을 가져오는 순간에 락이 걸립니다. 자동 증가 락은 테이블에 1개만 존재하기 때문에, 한 쿼리에서 락을 획득하여 채번중이라면 다음 쿼리는 락을 대기해야 합니다. 하지만 아주 짧은 순간만 걸렸다가 즉시 해제되므로 대부분의 경우 문제가 되지 않는다고 합니다.
자동 증가 락은 잠금을 최소화하기 위해 한 번 증가하면 절대 자동으로 줄어들지 않는다. 그리고 앞서 설명하였듯 이는 트랜잭션과도 무관합니다.
Intention Lock
- Table-level lock
- row에 대해서 나중에 어떤 row-level 락을 걸 것인지 알려주기 위해 미리 table-level에 걸어두는 lock입니다.
그동안 본 lock들은 row에 대한 lock이지만 table에 걸리는 락도 있습니다. 그것이 바로 Intention Lock입니다. 동작이 특이하고 비교적 유명하지 않아 간과하기 쉬워 꼭 익혀놓는 것을 추천드립니다!
특징
- IS, IX 락은 여러 트랜잭션에서 동시에 접근이 가능합니다. (서로 block하지 않습니다.). 하지만 동일한 row에 row-level의 실제 lock (S 또는 X)을 획득하는 과정에서 동시 접근을 막거나 허용하는 제어를 하게 됩니다.
- LOCK TABLES, ALTER TABLE, DROP TABLE 이 실행될 때는 IS, IX 를 모두 block하는 table-level 락이 걸립니다. 즉 IS, IX lock 을 획득 하려는 트랜잭션은 대기상태로 빠집니다.
- 반대로 IS, IX 락이 이미 걸려있는 테이블에 위의 쿼리를 실행하면 를 실행하면 해당 트랜잭션이 대기상태로 빠집니다.
SELECT … LOCK IN SHARE MODE 이 실행되면
1. Intention Shared Lock (IS) 이 테이블에 걸립니다.
2. row-level 에 S-Lock 이 걸립니다.
SELECT … FOR UPDATE, INSERT, DELETE, UPDATE 이 실행되면
1. intention exclusive lock (IX) 이 테이블에 걸립니다.
2. row-level 에 X-Lock 이 걸립니다.
왜 굳이 이런 형태의 락이 필요한 것일까요? 여러개의 트랜잭션들이 gap 안의 다른 위치에 INSERT를 동시 수행할 때 기다릴 필요가 없도록 하는것이 목적입니다. 예시를 들어 설명하자면,
- 예) row-level의 write이 일어나고 있을때 테이블 스키마가 변경되서는 안됩니다. write query의 경우 이미 IX 락을 획득한 상태이기 때문에 해당 테이블의 스키마가 변경되는것을 막을 수 있습니다.
INSERT Intention Lock이 대표적으로 주의해야할 락입니다. 이 Intention Lock은 INSERT 구문이 실행될 때 InnoDB 엔진 내부적으로 implicit하게 획득하는 특수한 형태의 gap lock입니다.
- 예) pk=3, pk=6의 레코드가 존재하는 테이블이 존재
- A 트랜잭션에서 pk=5에 INSERT, B 트랜잭션에서 pk=4에 INSERT시도
- 만약 일반적인 gap lock 사용한다면:
- A트랜잭션이 pk=5를 INSERT하는 과정에서 pk=3~5에는 gap lock 걸림
- B트랜잭션이 pk=4에 INSERT 시도시 pk=3~5에 gap lock이 걸려있기때문에 A가 트랜잭션이 완전히 종료될 때 까지 기다려야 한다.
- 대기시간 존재!
- Insert Intention Lock 사용시:
- A트랜잭션이 pk=5를 INSERT하는 과정에서 pk=3~5에는 insert intention lock 걸림
- B트랜잭션이 pk=4에 INSERT 시도시 pk=3~5에 insert intention lock이 걸려있더라도 pk가 겹치지 않기때문에 바로 진행 가능
- 대기시간 없음!
- 실제 InnoDB의 동작 방식
- INSERT될 row에 대해서 exclusive lock을 걸기 전에 먼저 insert intention lock을 건다는 점을 주의해야 합니다. (실행 순서)
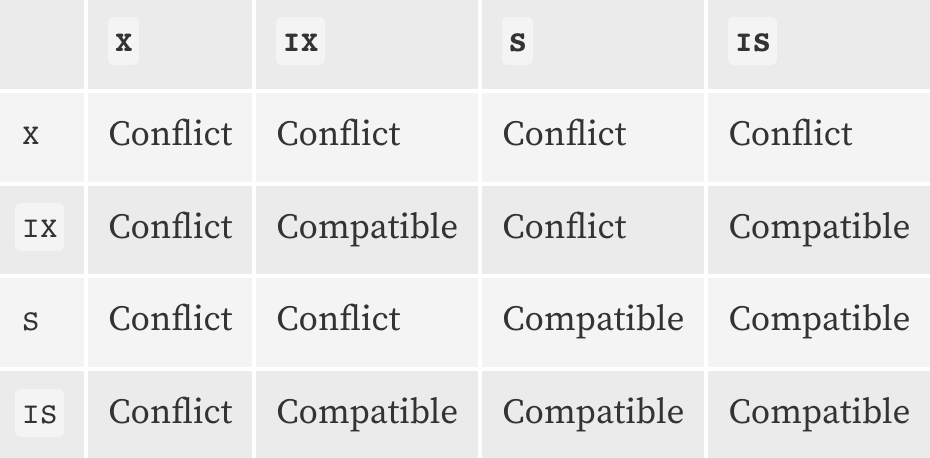
- 또한 기존 S락, X락과 어떻게 호환이 되는지도 살펴봐야 합니다. 아래는 Share lock, Exclusive lock, Intention lock이 각각 다른 트랜잭션에서 사용될때, 충돌(Conflict, 대기상태 빠짐), 또는 호환(Compatible, 대기상태에 빠지지 않음)이 되는지에 대해 정리된 표입니다.
AUTO-INC Lock
- 여러 트랜잭션이 동시에 실행될때 AUTO_INCREMENT 컬럼의 값을 일관성 있게 증가시키기 위해 필요한 lock입니다
- AUTO_INCREMENT 방식에대해서 InnoDB에서 몇가지 모드를 제공하는데 자세한 내용은 다음을 참조해주세요. MySQL - InnoDB Auto Increment 성능최적화
REPEATABLE READ에서의 락 트리거 조건
중요한 것은 어떤 상황에서 어떤 락이 쓰이는지일 것 같습니다. 일반적으로 인덱스는 확인하지만 락에 대해서는 간과하기 쉽습니다. 여기서 내가 만든 쿼리가 데드락을 유발하지는 않을 지, 동시성이 떨어지지 않을 지 챙기는 것이 좋습니다.
잠금 읽기란 명령문 의 경우 잠금은 명령문이 고유한 검색 조건이 있는 고유 인덱스를 사용하는지, 범위 유형 검색 조건을 사용하는지에 따라 달라집니다. (FOR UPDATE, FOR SHARE, UPDATE, DELETE)
- 고유한 검색 조건이 있는 unique index의 경우, InnoDB는 발견된 인덱스 레코드만 잠그고, 그 앞의 갭은 잠그지 않습니다.
- 다른 검색 조건의 경우, 갭 잠금 또는 다음 키 잠금을 사용하여 스캔된 인덱스 범위를 잠그고 범위로 덮인 갭에 다른 세션이 삽입하는 것을 차단합니다.
- 조금 더 자세히 설명하면 다음과 같습니다.
- Primary Key와 Unique Index쿼리의 조건이 1건의 결과를 보장하는 경우, Gap Lock은 사용되지 않고 Record Lock만 사용됩니다. 쿼리의 조건이 1건의 결과를 보장하지 못하는 경우, Record Lock + Gap Lock이 동시에 사용됩니다. (레코드가 없거나, 여러 컬럼으로 구성된 복합 인덱스를 일부 컬럼만으로 WHERE 조건이 사용된 경우 포함)
- Non-Unique Secondary Index쿼리의 결과 대상 레코드 건수에 관계없이 항상 Record Lock + Gap Lock이 사용됩니다
'Backend > DB' 카테고리의 다른 글
| MySQL DEAD LOCK (1) | 2024.12.28 |
|---|---|
| MySQL의 JSON 타입 사용 시 주의사항 (2) | 2024.12.28 |
| SELECT ... FOR UPDATE - NO WAIT & SKIP LOCKED (0) | 2024.12.28 |
| COUNT 쿼리의 실행계획, 인덱싱 (0) | 2024.12.28 |
| 풀스캔 쿼리 패턴 및 튜닝 (1) | 2024.12.26 |