

1. 들어가며
오늘은 Kafka의 클라이언트인 Producer와 Client가 브로커 노드와 통신하기 위해 사용하는 NetworkClient에 대해 알아보도록 하겠습니다.
NetworkClient란?
Kafka 클라이언트와 브로커 노드들의 연결 상태를 관리하고 브로커 노드로 데이터를 쓰거나 브로커 노드에서 데이터를 읽는 역할을 한다.

클라이언트가 브로커에 보낼 ClientRequest를 만들면, NetworkClient가 중간에서 요청을 중개해줍니다. 그림을 보면 알 수 있듯이 NetworkClient는 Client 측에 있는 구현체입니다. 오늘은 이 구현체가 어떻게 I/O Multiplexing을 통해 빠른 동시 연결을 달성하는지 알아보도록 하겠습니다.
오늘 글은 다음 글과 함께 내부 코드를 보며 작성되었습니다 :)
https://d2.naver.com/helloworld/0853669
2. NetworkClient
1) API
| 메서드 | 설명 |
| boolean isReady(Node node, long now); | 노드에 요청을 보낼 수 있는 상태인지 확인 |
| boolean ready(Node node, long now); | 노드에 요청을 보낼 수 있는 상태인지 확인하고 필요한 경우 Connection 생성 |
| long connectionDelay(Node node, long now); | 다음 연결 시도까지 얼마나 기다려야 하는지 확인 |
| boolean connectionFailed(Node node); | 노드로의 연결이 끊겼는지 확인 |
| void close(String nodeId); | 노드로의 연결 닫기 |
| void send(ClientRequest request, long now); | 보내야 할 요청을 큐에 저장(나중에 준비되면 요청을 전송) |
| List<ClientResponse> poll(long timeout, long now); | 실제 I/O 수행 및 받은 응답을 가져옴 |
| Node leastLoadedNode(long now); | 가장 요청을 적게 받은 노드를 선택 |
| int inFlightRequestCount(); | 브로커로 전송되었지만 응답을 아직 받지 못한 요청들의 총합 |
| int inFlightRequestCount(String nodeId); | 특정 브로커로 전송되었지만 응답을 아직 받지 못한 요청들의 수 |
| void wakeup(); | I/O 수행을 기다리고 있는 스레드를 깨움 |
NetworkClient에서 제공하는 API들입니다. 대부분이 노드의 상황을 파악하고 연결을 관리하는 것임을 알 수 있습니다. 또한 send 메서드와 같이 전송을 담당하기도 합니다. 주의할 점은 이 전송은 즉시 전송이 아닌 큐에 저장하고 나중에 준비되면 요청을 전송하는 방식이라는 점입니다.
2) ClusterConnectionStates
ClusterConnectionStates란?
NetworkClient에서 브로커의 연결 상태를 관리하는 구현체.
ClusterConnectionStates는 Kafka 클라이언트와 연결되어 있는 브로커의 연결 상태에 관한 정보를 브로커마다 NodeConnectionState 객체에 기록합니다. 다음 그림에서 노란색 박스에 해당하는 NodeConnectionState에는 현재 연결 상태를 나타내는 ConnectionState와 마지막으로 연결을 시도했던 시간 정보가 기록됩니다.
Brocker의 ConnectionState를 보면 READY, DISCONNECTED가 있는 것을 볼 수 있습니다. 이렇듯 브로커 연결 정보는 여러 상태를 가질 수 있습니다.
| 연결 상태 | 설명 |
| DISCONNECTED | 브로커와 연결이 끊긴 상태 |
| CONNECTING | 소켓을 생성하고 연결을 생성 중인 상태 |
| CHECKING_API_VERSIONS | 연결이 생성되었고 브로커와 API 버전이 호환되는지 확인 중인 상태 |
| READY | 브로커로 요청을 전송할 수 있는 상태 |
각 상태는 다음과 같은 관계도를 가집니다.
- 최초 연결: Kafka 클라이언트가 브로커와 연결을 시도하면 ConnectionState는 다음 그림과 같이 CONNECTING 상태와 CHECKINGAPIVERSION 상태를 거쳐 최종적으로 READY 상태가 됩니다.
- 요청 및 응답 가능: Kafka 클라이언트가 브로커 노드와 요청과 응답을 주고받으려면 브로커와의 연결 상태가 READY 상태여야 합니다.
- 문제 발생: 만약 각 연결 단계에서 문제가 발생한다면 DISCONNECTED 상태로 바뀌고 브로커와 통신하기 위해 다시 연결을 시도합니다.
1) DISCONNECTED
Kafka 클라이언트와 브로커 노드의 연결이 끊긴 상태를 의미합니다.
브로커와 연결 상태가 DISCONNECTED 상태라면 브로커로 요청을 보내기 위해 다시 연결을 시도해야 합니다. 이때 Kafka 클라이언트가 특정 브로커와의 연결을 너무 빈번하게 재시도하지 않도록 최소한 reconnect.backoff.ms에 설정한 시간이 지난 이후에 재연결을 시도합니다.
예를 들면 다음과 같은 예시가 있습니다. 브로커 노드로의 연결 초기화가 실패한 경우, API 버전이 호환되지 않는 경우, 브로커 노드로 요청 전송이 실패한 경우, 요청이 전송되고 응답을 기다리다가 타임아웃이 발생한 경우, 일정 시간 동안 브로커로 새로운 요청을 보내지 않은 경우
2) CONNECTING
Kafka 클라이언트가 브로커와 연결을 시도할 때 CONNECTING 상태가 됩니다.
ConnectionState의 상태를 CONNECTING으로 변경하고 브로커와 통신하기 위한 SocketChannel을 생성합니다. 이때 생성되는 SocketChannel의 크기는 send.buffer.bytes에 설정된 송신 버퍼(send buffer size)의 크기와 receive.buffer.bytes에 설정된 수신 버퍼(receive buffer)의 크기입니다. 크기를 별도로 설정하지 않으면 송신 버퍼의 크기는 128KB이고, 수신 버퍼의 크기는 64KB입니다. 만약 값을 '-1'로 설정하면 실행하는 운영체제의 기본값인 SO_SNDBUF와 SO_RCVBUF가 적용됩니다.
3) CHECKINGAPIVERSIONS 상태, READY 상태
Kafka 클라이언트와 브로커가 통신하기 위해 필요한 객체들이 생성되면 CHECKINGAPIVERSIONS 상태로 ConnectionState의 상태를 변경합니다.
API가 문제없이 호환된다면 브로커의 연결 상태는 READY 상태가 됩니다.
Kafka 클라이언트와 브로커 사이에 연결이 수립되어 통신은 가능하지만 둘 사이의 API 버전이 맞지 않다면 정상적으로 동작할 수 없습니다. Kafka 클라이언트와 브로커가 호환되는 API 버전인지 확인하기 위해 Kafka 클라이언트는 자신의 API 버전 정보를 담은 ApiVersionRequest를 생성해서 브로커로 전송합니다. 그러면 브로커가 호환되는 버전인지를 판단해서 ApiVersionResponse를 Kafka 클라이언트에 돌려준다. Kafka 클라이언트는 이 응답을 통해 API 호환 여부를 알 수 있습니다.
- IdleExpiryManager
IdleExpiryManager란?
불필요한 연결을 정리하기 위해 사용하는 구현체입니다.
READY 상태인 브로커를 일정 기간 사용하지 않으면 연결이 정리될 수 있습니다. 여기서 정리를 맡는 것이 IdleExpiryManager입니다.
NetworkClient는 브로커와 연결된 SocketChannel들을 Java NIO의 Selector에 등록한 다음 비동기로 연산을 수행합니다.
Java NIO가 낯선 분이라면
NetworkClient의 poll() 메서드가 주기적으로 실행되면서 Selector에 등록된 SocketChannel 중 이벤트가 있는 것들을 그때그때 비동기 방식과 논블로킹 방식으로 처리합니다. IdleExpiryManager는 특정 SocketChannel에 어떤 이벤트가 처리되었을 때 그 시간을 기록해 두며, 이 시간을 기준으로 브로커 연결을 LRU(Least Recently Used) 알고리즘으로 관리합니다.
Java NIO가 낯선 분이라면: https://sightstudio.tistory.com/15 와 함께 이전에 제가 작성한 https://rawshrimpsushi.tistory.com/35를 참조해주세요! 비동기 서버 프로그래밍에 대한 이해가 필요합니다 :)
- InFlightRequests
InFlightRequests란?
이전에 보낸 요청에 대한 응답을 받기 전에 다음 요청을 전달할 수 있도록 하는 HOL Blocking을 방지해주는 request 구조.
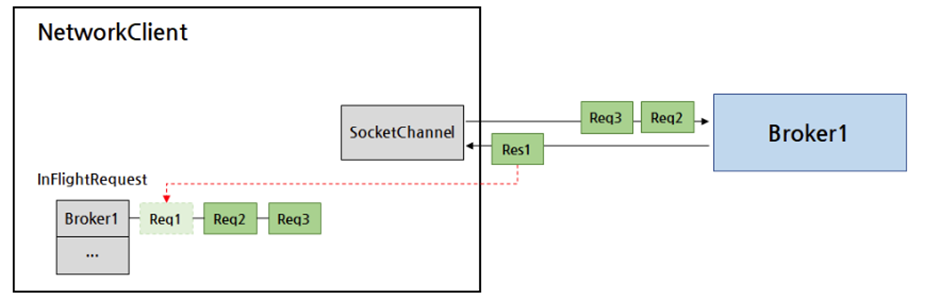
NetworkClient는 각 브로커로 전송한 요청을 Deque라는 자료구조에 저장합니다.
그림은 브로커로 순차적으로 Req1, Req2, Req3가 전송된 상황입니다.
브로커로부터 응답이 도착하면 그 브로커에 보냈던 요청을 저장해둔 Deque의 가장 앞쪽에서 요청을 하나 제거하고 응답을 처리합니다. 만약 요청에 대한 응답에 오류가 있다면 Deque의 가장 앞에 있던 요청을 가장 뒤로 다시 넣고 요청을 브로커에 재전송합니다.
- Selector
Kafka 특성 상 수많은 연결들이 있을 것입니다. 이 수많은 연결마다 스레드를 연다면 Context switch가 너무 잦아져서 효율이 급격히 저하될 것입니다. 이런 문제에 대해 다양한 해결법이 나와있는 상황입니다. Coroutine, Erlang VM, 비동기 I/O 등이 있을텐데 자바의 경우 비동기 I/O인 Java의 NIO를 통해 문제를 해결합니다.
Java NIO는 다음 그림과 같이 하나의 스레드가 Selector라는 컴포넌트를 두고 여러 SocketChannel을 관리할 수 있게 합니다. 스레드는 Selector를 사용해서 Selector에 등록된 SocketChannel들 중 하나라도 읽거나 쓰는 등 뭔가를 할 수 있는 상황이 되면 바로 알 수 있습니다. 이런 방식을 SocketChannel의 '멀티플렉싱'이라고 합니다.
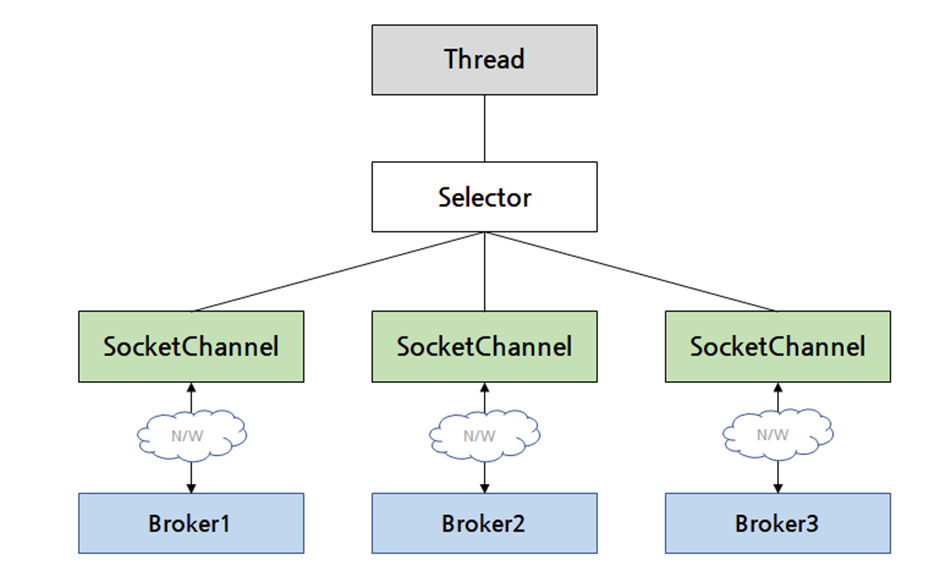
마찬가지로 https://rawshrimpsushi.tistory.com/35 의 EPOLL을 보시면 이해하기 편할 것이라 생각합니다 :)
소켓 프로그래밍 - 블로킹, 논 블로킹, 비동기, epoll, IOCP, IO Uring
1. 들어가며 게임을 만들며 게임 서버가 필요한 로직이 들어간다면 Photon, 프라우드넷 등 다양한 네트워크 엔진을 고려하게 됩니다. 모두 유용한 도구이고 특히 프라우드넷의 경우 마비노기 영
rawshrimpsushi.tistory.com
위 글에서는 C에서만 살펴봤으므로 Java에서는 구체적으로 어떻게 코드로 구현되는지 살펴보겠습니다.
// Java NIO Selector 생성
Selector selector = Selector.open();
// Java NIO SocketChannel 생성
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false); // 논블로킹 설정
socketChannel.connect(new InetSocketAddress(node.host(), node.port());
// Selector에 SocketChannel 등록
SelectionKey selectionKey = channel.register(selector, SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
// 특정 채널의 interestSet 변경
selectionKey.interestOps(SelectionKey.OP_READ | SelectionKey.OP_WRITE);
// select() 메서드를 통해 이벤트가 발생할 때까지 대기
selector.select(timeout);
// 이벤트가 발생한 채널을 순회하며 처리
// 등록한 브로커 중 필요한 연산을 할 수 있는 SocketChannel의 SelectionKey
Set<SelectionKey> selectedKeys = selector.selectedKeys();
// SelectedKeys 순회
Iterator<SelectionKey> iterator = selectedKeys.iterator();
while(iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
// ... 실행 코드
}
if (key.isWritable()) {
// ... 실행 코드
}
...
}
- MetaData
MetaData란?
Kafka 클라이언트가 알아야 할 Kafka 클러스터의 메타데이터와 그 메타데이터를 갱신하기 위한 동작이 정의되어 있는 Data입니다.
지금까지는 NetworkClient가 특정 브로커와 통신하는 방법에 대해 알아봤습니다. 단, Kafka 클라이언트가 접속할 브로커 주소 정보를 알고 있다는 가정입니다. 하지만 Kafka 클라이언트의 사용자는 메시지를 전송하거나 읽기 위해 어떤 브로커에 접속해야 하는지 모릅니다. 데이터의 접근 포인트로 클러스터에 있는 '토픽' 이름만 알고 있을 뿐입니다.
결론부터 이야기 하자면 Kafka 클라이언트는 토픽의 파티션이 어떤 브로커에서 서비스되고 있는지 Metadata 클래스를 통해 알게 됩니다.
사용자로부터 ProducerRecord 객체를 넘겨받은 KafkaProducer는 내부적으로 다음 그림과 같은 순서로 브로커 주소를 알게 됩니다.

ProducerRecord를 전달받은 KafkaProducer는 Partitioner를 사용해 토픽의 몇 번 파티션으로 데이터를 전송해야 하는지 결정합니다. 하지만 여전히 그 파티션이 어떤 브로커 노드에 있는지는 모릅니다. 그래서 MetaData까지 접근하여 정보를 알아야 합니다.
MeataData에서 관리되는 정보
- 클러스터를 구성하고 있는 브로커 노드의 접속 정보 - SocketChannel을 생성하기 위한 주소 정보
- 사용하는 토픽에 대한 정보 - 사용하는 토픽이 몇 개의 파티션인지, 파티션의 복제본은 어떤 브로커에서 서비스되는지, 그 중 Leader는 어디에 있는지 등
물론 위의 정보는 클러스터가 운영되면서 언제든지 바뀔 수 있습니다. 따라서 MeatadataUpdater에서 해당 정보 갱신을 맡습니다.
'Backend > general' 카테고리의 다른 글
| RabbitMQ vs Kafka - 벤치마크 테스트 (0) | 2024.06.19 |
|---|---|
| RabbitMQ 아키텍처 (0) | 2024.06.19 |
| Kafka - Consumer 깊게 파헤치기 (1) | 2024.06.03 |
| Kafka - Producer 깊게 파헤치기 (1) | 2024.06.03 |
| Kafka - 기본 아키텍처 알아보기 (0) | 2024.06.03 |