

1. 들어가며
지금까지 RabbitMQ와 Kafka에 대해 자세히 알아봤습니다.
여러 메시지 큐가 있겠지만 그 둘만 다뤘던 이유는, 그 둘이 가장 널리 쓰이기도 하지만 여러 성능 테스트 결과 상반된 경향이 있었기 때문입니다.
오늘은 실제로 그 둘을 테스트 해보고 어떤 차이점이 있는지, 그리고 그 이유가 무엇인지 살펴보도록 하겠습니다.각각 결과를 살펴보면 각 Message Queue가 어디에 적합할 지 결론에 다다를 수 있을 것이라 생각합니다 :)
2. RabbitMQ vs Kafka
오늘 글은 다음 논문, 글들을 참조하여 쓰여졌습니다! 그래프는 모두 R로 작성되었습니다.
Dobbelaere, Philippe & Sheykh Esmaili, Kyumars. (2017). Kafka versus RabbitMQ: A comparative study of two industry reference publish/subscribe implementations: Industry Paper. 227-238.
Jay Kreps. (2014). Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines). https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
T, Sharvari & K, Sowmya. (2019). A study on Modern Messaging Systems- Kafka, RabbitMQ and NATS Streaming.
Simon MacMullen. (2012). RabbitMQ Performance Measurements, part 2.
https://www.rabbitmq.com/blog/2012/04/25/rabbitmq-performance-measurements-part-2
1) RabbitMQ Benchmark
RabbitMQ의 성능을 메시지 크기, 생산자 수, 소비자 수로 나눠 측정한 결과입니다.
- 메시지 크기
메시지 크기는 메시지 브로커 시스템의 성능에 큰 영향을 미치는 요소 중 하나입니다. RabbitMQ의 성능을 다양한 메시지 크기(100KB, 250KB, 500KB, 750KB, 1MB)로 측정한 결과는 다음과 같다.
consumer와 producer와 같은 종속 변인은 모두 1로 고정했습니다.
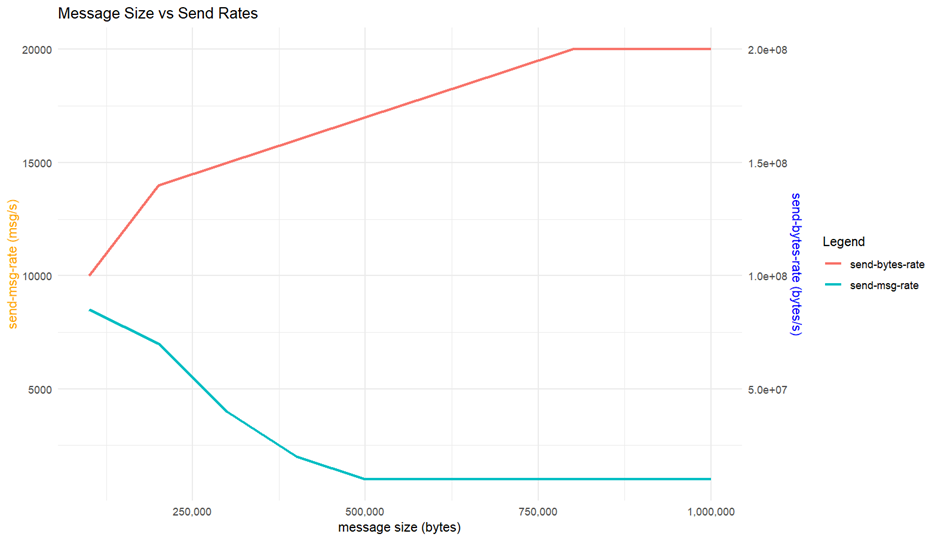
크기가 증가함에 따라 메시지 속도는 감소하지만 메세지 크기가 커진 만큼 라우팅 오버헤드가 줄어들어 실제 전송된 throughput은 증가합니다. 다만 0.8MB 이상의 크기에서는 네트워크 I/O에 한계가 있어 더이상 증가하지 않는 것을 볼 수 있습니다.
- 생산자(Producer)
producer의 수는 메시지 브로커의 처리 성능에 직접적인 영향을 미칩니다. producer가 많을수록 시스템은 더 많은 메시지를 동시에 처리해야 하며, 이는 브로커의 부하를 증가시킵니다. producer 개수를 1개부터 10개까지 늘리며 성능을 측정한 결과는 다음과 같습니다.
consumer의 경우 1개, minMsgSize는 1000 byte로 고정되어 있습니다.
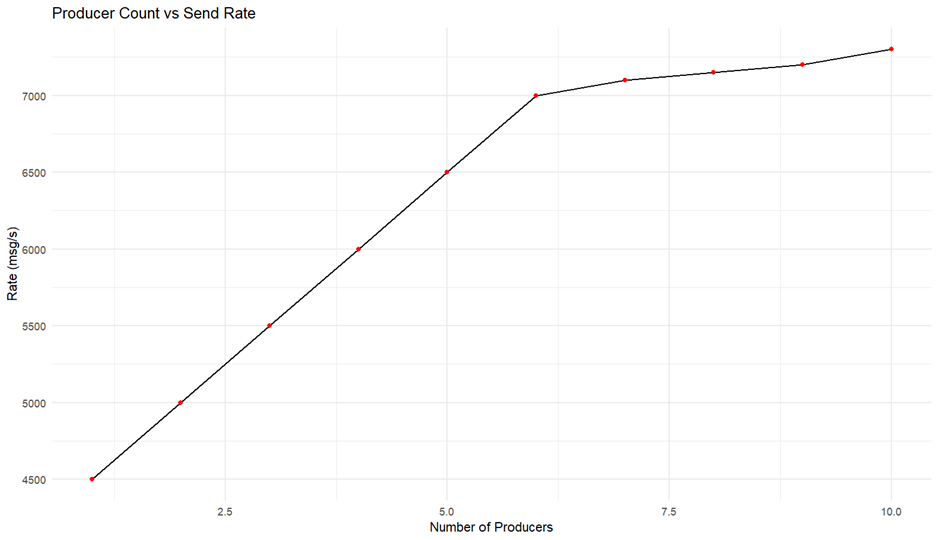
6개의 producer일 때 시스템 자원이 포화가 되었으며 그 전까지는 선형적으로 처리량이 증가하는 것을 알 수 있습니다. 이는 네트워크와 CPU 부하 처리량에 의존적이며 서버 성능에 따라 최대 처리량을 달성하기 위해 필요한 producer 수가 다름을 암시합니다.
- 소비자(Consumer)
consumer 수가 증가하면 브로커는 더 많은 메시지를 병렬로 전송해야 하며, 이는 시스템의 네트워크와 CPU 자원을 더욱 소모하게 됩니다. consumer 수를 1개부터 1000개로 늘리며 성능을 측정한 결과는 다음과 같습니다.
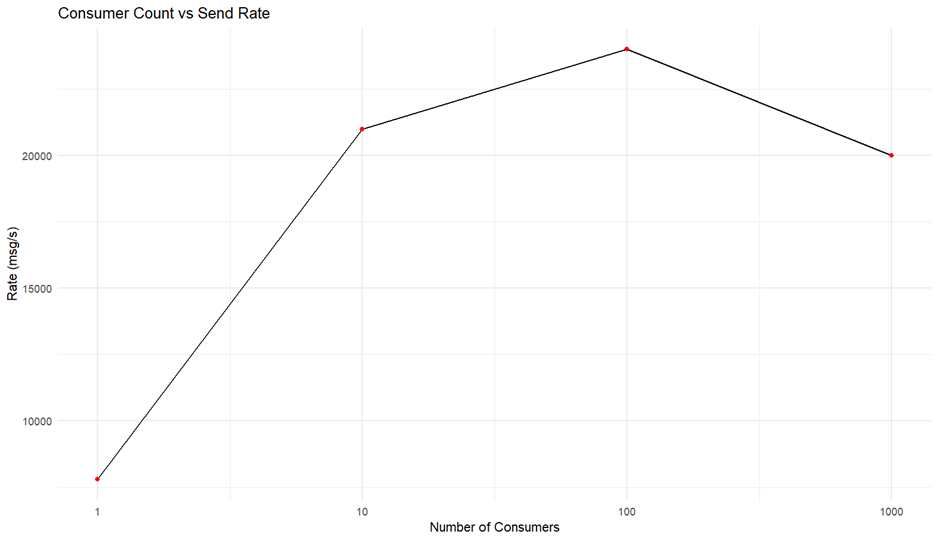
각 소비자는 병렬성이 생산자에 비해 소비자 수가 적을 때 소비자를 한 명 더 추가하면 성능이 향상됩니다. 단 일정 크기 이상의 consumer는 서로 race condition 상태를 악화시켜 오히려 성능이 떨어지는 모습을 볼 수 있습니다.
2) Kafka Benchmark
Kafka의 성능을 마찬가지로 메시지 크기, 생산자 수, 소비자 수로 나눠 측정한 결과입니다.
- 메시지 크기
RabbitMQ의 성능을 다양한 메시지 크기(10Byte, 100Byte, 1KB, 10KB, 100KB)로 측정한 결과는 다음과 같습니다. consumer와 producer와 같은 종속 변인은 모두 1로 고정했습니다. Kafka의 경우 기본 설정 상 1MB 이상의 메시지를 사용할 수 없으며, 설정을 바꾼다고 해도 권장하지 않습니다.
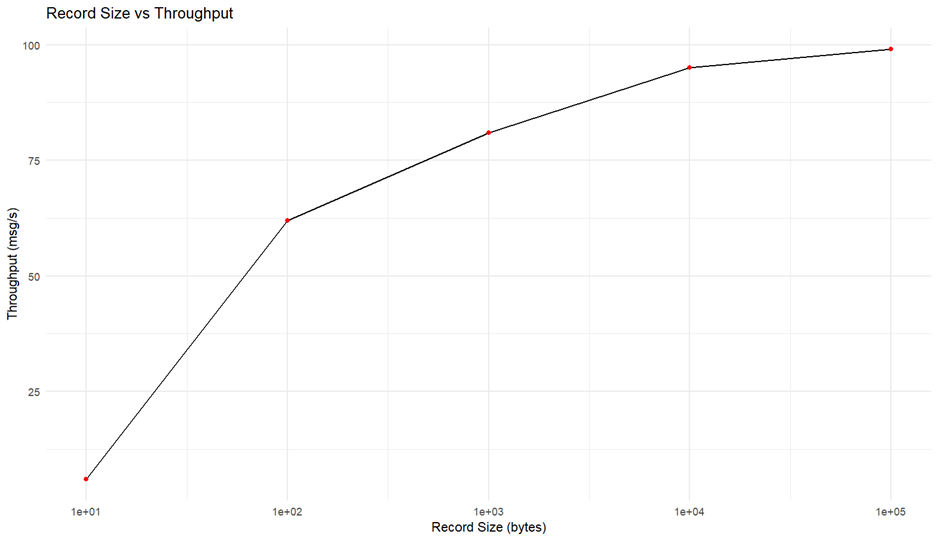
이는 RabbitMQ와 유사한 모습을 보이는데, 라우팅 오버헤드와 같은 것이 메세지 크기가 증가할 수록 감소하기 때문에 전체적인 throughput은 증가하는 것을 볼 수 있습니다. 하지만 Network I/O의 한계로 일정 크기 이상 증가하지는 않고 수렴합니다.
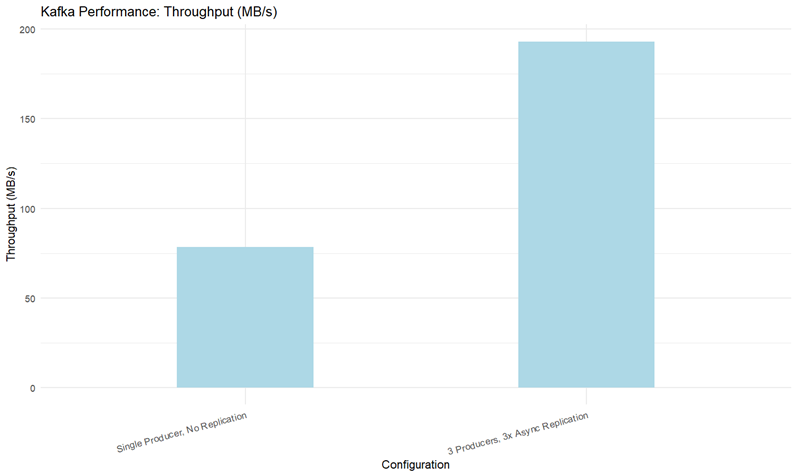
- 생산자(Producer)
RabbitMQ와 유사하게 선형적으로 증가합니다. Kafka 특성 상 많은 수를 테스트하기는 힘들었습니다.
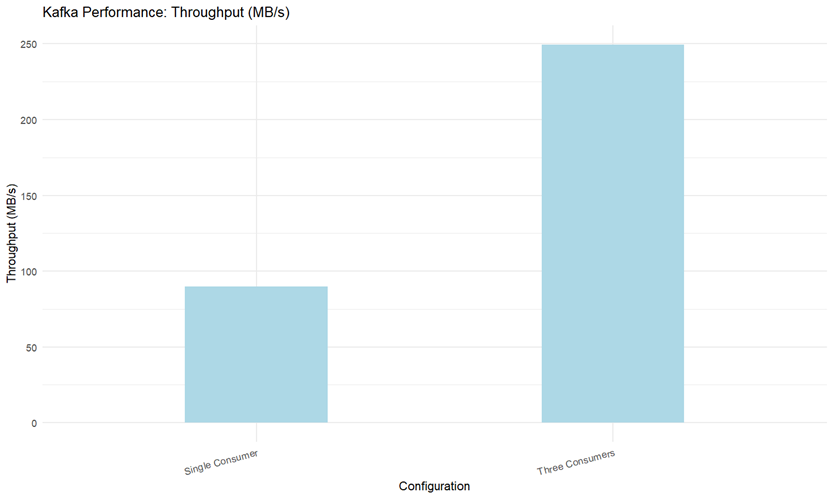
- 소비자(Consumer)
소비자 확장 역시 동일하게 선형적인 확장을 보입니다.
3) RabbitMQ vs Kafka Benchmark
이번에는 Kafka와 RabbitMQ를 직접 비교해보겠습니다. 메시지 크기, Producer, Consumer에 대한 것은 위에서 이미 살펴봤고, 각각 비교를 명확히 하기 위해 지연 시간(Latency)와 처리량(throughput)을 살펴보겠습니다.
- 지연 시간(Latency)
원활한 서비스에서는 전체 트래픽이 일정 지연 시간 이상으로 수행되는 것이 중요하기 때문에 전체 메세지에서의 평균 지연 시간뿐만 아니라 꼬리 지연 시간(최대 지연시간이 소요된 메시지)를 측정하는 것에도 의미가 큽니다. 따라서 각 시스템의 평균 지연 시간과 더불어 퍼센타일을 나눠 99번째 퍼센타일(p99) 이상의 지연 시간을 비교하였습니다. 지연 시간 측정은 지연 시간 측정은 100MB 이하의 처리량 조건에서 수행되었습니다.
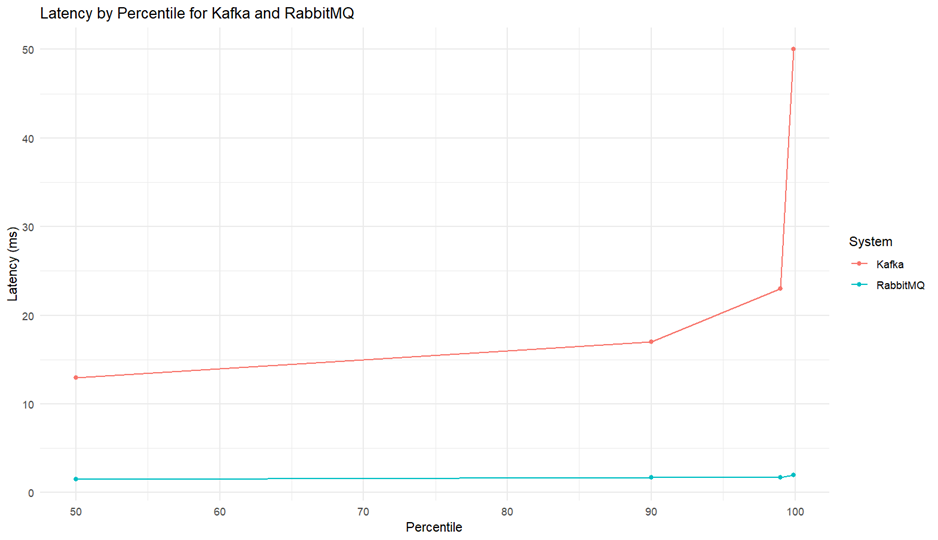
- 평균 지연 시간: Kafka와 RabbitMQ 모두 수 밀리초(ms) 내외의 낮은 지연 시간을 기록하였습니다. 이는 두 시스템 모두 기본적인 메시지 전송 작업에서 빠른 응답 속도를 제공한다는 것을 의미합니다.
- p99 이상의 지연 시간: Kafka의 경우, 꼬리 지연 시간이 매우 증가한 것을 볼 수 있습니다. 구체적으로, Kafka의 p99 이상의 지연 시간은 평균 지연 시간 대비 수백 배 낮아졌습니다. 반면, RabbitMQ의 p99 이상의 지연 시간은 평균 지연 시간에 비해 몇 배 정도만 증가하여 비교적 일관된 성능을 보였습니다.
- 처리량(throughput)
처리량은 시스템이 단위 시간당 처리할 수 있는 메시지의 양을 나타내며, 성능 비교의 또 다른 중요한 지표입니다. Producer와 consumer 수를 1개로 고정한 뒤 전송 메시지 수를 늘려가며 비교를 수행하였습니다.
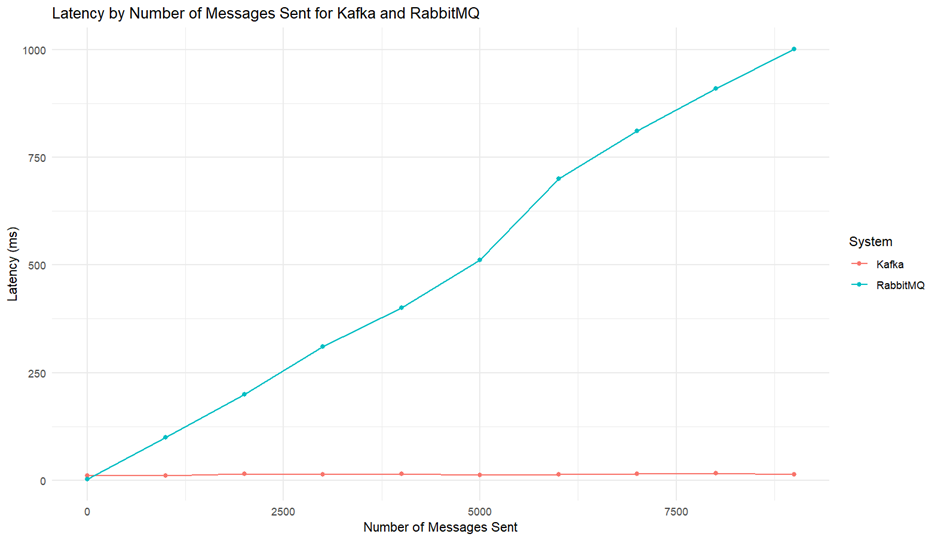
- Kafka의 처리량: Kafka는 처리량이 증가하여도 무리 없이 높은 성능을 유지하였습니다. 수백 MB의 처리량에서도 안정적인 성능을 보였으며, 지연 시간 역시 크게 증가하지 않았습니다. 이는 Kafka가 높은 처리량을 처리할 수 있는 강력한 아키텍처를 가지고 있음을 의미합니다.
- RabbitMQ의 처리량: RabbitMQ는 초기 처리량 증가에 잘 대응하였으나, 수백 MB 이상의 처리량이 되자 지연 시간이 급격히 증가하였습니다. 이 때의 지연 시간은 수백 배까지 증가하여, 높은 처리량 조건에서의 성능 저하가 뚜렷하게 나타났습니다.
4) 결과 분석
BenchMark 결과 다음과 같은 공통점과 차이점을 보였습니다.
- 공통점
- 지연 시간: 적절한 환경에서, RabbitMQ와 Kafka 모두 수 밀리초(ms)의 낮은 지연 시간을 기록하였습니다. 이는 두 시스템이 기본적인 메시지 전송 작업에서 빠른 응답 속도를 제공할 수 있음을 의미합니다.
- 프로듀서와 컨슈머 수의 영향: 프로듀서와 컨슈머 수를 늘리면 두 시스템 모두 선형적인 처리량 증가를 보였습니다. 이는 프로듀서와 컨슈머 수의 증가는 메시지 병렬 처리 능력을 향상시켜 전체 처리량을 높일 수 있음을 보여줍니다. 단, 컴퓨팅 파워에 제한이 있기 때문에 적절한 숫자가 있는 것으로 보입니다.
- 메시지 크기의 영향: 메시지 크기를 늘릴 경우, 라우팅 오버헤드가 감소하여 전체 처리량이 증가하였습니다. 큰 메시지를 처리할 때는 작은 메시지보다 상대적으로 더 적은 오버헤드가 발생하여 처리 효율이 높아지는 것으로 나타났습니다. 단 Kafka의 경우 메시지 크기에 제약이 큰 편입니다.
- 차이점
- 꼬리 지연 시간(Tail Latency): Kafka는 RabbitMQ에 비해 꼬리 지연 시간(p99 이상의 지연 시간)이 더 길게 나타났습니다. 이는 Kafka의 일부 메시지가 예상보다 수백배 늦게 도착할 수 있음을 보여줍니다. 반면, RabbitMQ는 평균 지연 시간과 p99 지연 시간의 차이가 비교적 작아, 일관된 지연 시간을 유지하는 경향을 보였습니다.
- 처리량(Throughput): 처리량이 수백 MB 이상으로 증가할 때, RabbitMQ는 지연 시간이 급격히 증가하는 반면, Kafka는 처리량 증가를 무리 없이 소화할 수 있었습니다. 이는 Kafka의 설계가 높은 처리량을 처리하는 데 더 최적화되어 있음을 나타냅니다. RabbitMQ는 중간 수준의 처리량까지는 안정적인 성능을 보였지만, 매우 높은 처리량에서는 성능 저하가 뚜렷했습니다.
5) 원인 분석
이렇게 차이가 벌어진 이유를 각각의 코드와, 여러 논문, 글들을 참조하면서 작성했습니다. 혹시 다른 의견이 있으시다면 언제든지 알려주시면 감사하겠습니다 :)
- 아키텍처
Kafka는 독립적인 파티션과 그에 따른 각각의 offset 조회로 병렬성을 선형적으로 달성하여 throughput이 매우 높습니다.
반면 RabbitMQ는 큐잉 방식을 사용하기 때문에 전체적인 throughput에서 Kafka에 비해 부족할 수 밖에 없습니다.
- 네트워크 I/O
Kafka의 Java NIO 기반 비동기 I/O 모델은 대규모 네트워크 요청을 효과적으로 처리하며, 이는 높은 처리량을 가능하게 합니다. 이는 단일 스레드가 다수의 네트워크 연결을 관리할 수 있게 하며, I/O 작업의 병목 현상을 줄입니다.
RabbitMQ의 Erlang 기반 비동기 메시지 패싱 모델은 낮은 지연 시간과 높은 동시성을 제공하여 실시간 메시지 전달에 최적화됩니다. Connection이라는 물리 단일 연결을 channel이라는 virtual 연결로 추상화하긴 했지만 기본적으로 하나의 queue에는 하나의 연결을 가정하고 있다고 봐야 합니다. 따라서 높은 throughput보단 메시지의 정확성과 낮은 latency 지향적이라고 해석할 수 있습니다.
이처럼 이벤트 루프 기반 JAVA NIO와 Erlang의 단일 연결 가상화는 지향점이 다르며 각각 Message Queue의 설계 이념을 엿볼 수 있습니다.
- 디스크 I/O
Kafka는 데이터를 순차적으로 디스크에 기록하며, 이는 디스크 I/O 성능을 극대화합니다. 데이터가 배치로 기록되어 디스크 쓰기 성능을 최적화합니다. 이는 랜덤 액세스에 비해 매우 빠른 디스크 쓰기 성능을 제공합니다. 처리량을 크게 향상시키면서 파이프라인의 모든 단계(생산, 중개 및 소비)에서 일괄 처리를 사용합니다.
이는 OS 페이지 캐시에 의존합니다. 운영 체제의 미리 읽기 전략은 로그 파일 덩어리를 순차적으로 소비하는 소비자의 선형 읽기 패턴을 최적화하는 데 매우 효과적입니다. 쓰기 버퍼링은 메시지가 로그에 추가될 때 자연스럽게 이 캐시를 채우며, 이는 대부분의 소비자가 크게 뒤처지지 않는다는 사실과 결합하여 매우 높은 캐시 적중률을 의미하므로 디스크 측면에서 읽기가 거의 비용 없이 이루어집니다.
Kafka의 경우 소비자가 생산자보다 느린 경우(일반적인 경우일 수 있음) 읽기가 완료되기 전에 패킷을 디스크에서 캐시로 전송해야 합니다. 순차적 디스크 액세스를 제공하는 아키텍처를 사용하더라도 효과가 중요하지 않은 느린 소비자뿐만 아니라 캐시가 삭제되는 빠른 소비자의 경우에도 대기 시간 값이 급격히 증가합니다. 또한 기본적으로 Disk I/O이기 때문에 In-Memory를 기반으로 동작하는 RabbitMQ에 비해 latency가 떨어지는 모습을 보입니다.
이는 Kafka의 꼬리 지연 시간이 긴 이유입니다. 캐시 조회가 실패한 메시지들이 Disk I/O를 거치면서 수백배의 지연이 된다고 볼 수 있습니다.
RabbitMQ는 주로 메모리 기반 큐잉을 사용하여 즉각적인 메시지 처리를 가능하게 하며, 이는 낮은 지연 시간을 보장합니다.
다만 RabbitMQ가 최대 로드에 가깝게 실행되면(예외 설정) 브로커는 계산에 필요한 메모리를 확보하기위해 디스크에 패킷을 쓰기 시작합니다. 이때문에 지연 시간이 급격히 증가할 수 있습니다. 이는 RabbitMQ에서 수백 MB 이상의 thoroughput을 처리할 때 지연 시간이 수백배 이상 증가하는 이유입니다.
- 사용 언어
Kafka가 Java로 작성되었다는 점은 Kafka 동작에 있어 큰 영향을 끼칩니다. Kafka가 JVM에서 실행되고 Kafka가 큰 청크를 할당할 때 큰 메시지가 더 긴 가비지 수집 일시 중지를 유발할 수 있다는 점입니다. 또한 Kafka가 ZooKeeper 세션을 포기하지 않도록 Zookeeper에 대한 더 긴 시간 초과 값을 구성해야 하는 지점까지 부정적인 영향을 미칠 수도 있습니다. 정교하지 않은 잠금 메커니즘과 가비지 수집 프로세스로 인해 훨씬 더 많은 가변성을 가진 JVM에서 실행되는 Kafka 특성상 Rabbit MQ의 Erlang VM보다 오류율이 더 높게 나타났습니다.
RabbitMQ는 RabbitMQ는 Erlang/OTP 플랫폼 위에서 실행됩니다. Erlang의 경량 프로세스 모델과 비동기 메시지 패싱은 매우 낮은 지연 시간을 제공합니다. 각 연결은 독립된 프로세스로 처리되며, 이는 동시성 및 병렬 처리에 강점을 줍니다.
'Backend > general' 카테고리의 다른 글
| RabbitMQ 아키텍처 (0) | 2024.06.19 |
|---|---|
| Kafka - Network Client 깊게 파헤치기 (2) | 2024.06.19 |
| Kafka - Consumer 깊게 파헤치기 (1) | 2024.06.03 |
| Kafka - Producer 깊게 파헤치기 (1) | 2024.06.03 |
| Kafka - 기본 아키텍처 알아보기 (0) | 2024.06.03 |