

1. 들어가며
콜레이션이란? 하면 저는 사실 부끄럽게도 처음 듣는 단어였습니다. 다만 이번에 Real MySQL을 학습하면서 문자열을 다룰 때 몰라서는 안 될 정보라는 걸 알게 된 만큼 이 글을 읽는 분들도 꼭 알아가시길 바랍니다!
2. 콜레이션 (Collation)
정의 및 특성
- 문자를 비교하거나 정렬할 때 사용되는 규칙
- 문자집합(Character Set)에 종속적
- 문자와 코드값(코드 포인트)의 조합이 정의되었는 것이 문자집합
- e.g. "A=U+0041", "B=U+0042", "a=U+0061", "b=U+0062"
- MySQL에서 모든 문자열 타입 컬럼은 독립적인 문자집합과 콜레이션을 가질 수 있습니다.
- 사용자가 특별히 지정하지 않는 경우, 서버에 설정된 문자집합의 디폴트 콜레이션으로 자동 설정됩니다. (서버의 문자 집합도 따로 정의하지 않았다면 default는 utf8mb4_0900_ai_ci 입니다.)
무언가 정의만 보면 비교와 정렬에 쓰이는 건 알겠는데, 구체적으로 와닿지 않는 것이 사실입니다. 조금 더 자세히 종류와 용례를 비교해가며 알아보도록 하겠습니다.
종류
종류를 보기에 앞서 콜레이션의 네이밍 컨벤션부터 알아보겠습니다. 네이밍 컨벤션은 수많은 종류에 대해 구분할 수 있는 하나의 기준이 됩니다.
문자집합_언어종속_UCA버전_민감도
- 문자집합: utf8mb4, latin1, euckr
- 언어종속: 특정 언어에 대해 해당 언어에서 정의한 정렬 순서에 의해 정렬 및 비교를 수행 (다른 언어들에는 적용되지 않음. ex: tr 혹은 turkish)
- UCA 버전: Unicode Collation Algorithm Version
- 민감도
- a: Accent
- c: case
- k: kana
- i: insensitive
- s: sensitive
- bin: binray
- 예를 들어 _ai 인 경우 accent insensitive라는 뜻입니다.ㅣ
SHOW COLLATION으로 사용 가능한 목록을 확인할 수 있습니다. 위의 네이밍 컨벤션과 조합해서 보면 어떤 의미인지 알기 쉬울 것입니다.

동작 방식

- 문자 가의 포인트는 U+AC00 으로 3바이트가 필요합니다.
- 이에 따라 맨 오른쪽 값처럼 3바이트 시퀀스 값을 완성시킵니다.
- 저장 방식 자체가 저렇게 된다고 보시면 됩니다.

- DUCET: 유니코드 문자 별로 가중치 값이 정의된 것.
- 예를 들어 한글 문자 ㄱ의 가중치는 3131. [대괄호] 안에 있는 것이 각각 primary weight, secondary weight, tertiary weigth입니다.
- 콜레이션에 따라 여기서 사용되는 가중치가 달라집니다.
- 한글 문자의 경우 분해해서 가중치 값을 조합한 후 비교합니다. 이에 따라 예상치 못한 비교가 이루어질 수 있는데 이는 다음에 살펴보겠습니다.
- ai_ci와 as_cs는 그러므로 각 가중치 값이 다릅니다.
기본적으로 MySQL 서버에 설정된 문자집합의 디폴트 콜레이션으로 글로벌하게 설정됩니다. 따로 디폴트 설정을 하지 않은 경우 위에서 언급한 것처럼 utf8mb4 문자집합과 utf8mb4_0900_ai_ci 콜레이션으로 설정됩니다.
또한 콜레이션은 데이터베이스/테이블/컬럼 단위로 독립적으로 지정 가능합니다.
- 다만 서로 다른 콜레이션을 가진 컬럼들 값을 비교 시 에러가 발생한다.
- 이를 위해 필요한 경우 COLLATE로 명시적으로 지정하거나 column의 collation을 변경하면 됩니다.
- 하지만 변경 시 일반 인덱스가 사용 불가능해집니다.
- 일반적으로 인덱스는 column에 설정된 콜레이션 기반으로 정렬되어 있기 때문에, 명시적으로 변경하는 경우 사용할 수 없게 됩니다.
- 그럴 경우 해당 collate로 함수 index를 생성해주면 됩니다.
또한 고유키도 콜레이션의 영향을 받습니다. 따라서 pk의 중복 여부 체크에 있어 콜레이션의 영향을 받게 됩니다. 예를 들어 대소문자 민감도가 없다면 고유키 저장 방식이 대소문자 민감도를 신경쓰지 않습니다.
위에서 기본 콜레이션 사용 시 주의해야할 점이 있다고 했는데요. 이는 "가"와 "ㄱㅏ"가 동일하게 인식된다는 점입니다.
근데 또 각 과 ㄱㅏㄱ, 가ㄱ은 다 다르다고 판정합니다. 다음 그림을 보며 살펴보겠습니다.


- 이처럼 기본 콜레이션을 사용하면서 한글을 비교할 경우 예상과 다르게 동작할 수 있다.
- mySQL의 동작 버그는 아니고 다 명시되어 있습니다.
- 근데 이게 표준값을 바꾸는 것이다 보니, 한글에서는 이렇게 동작하는 걸 인지하고 쿼리에서 조건을 거는 것도 방법이입니다.
- 아래 쿼리처럼 하면 col 인덱스도 탈 수 있고 and 조건에서 ㄱㅏ을을 걸러낼 수도 있습니다.
SELECT *
FROM tab
WHERE col='가을' AND (col='가을' COLLATE utf8mb4_unicode_520_ci)
즉 다음 표를 참고하여 비교 대상 문자의 인식 여부를 잘 따져봐야 합니다.

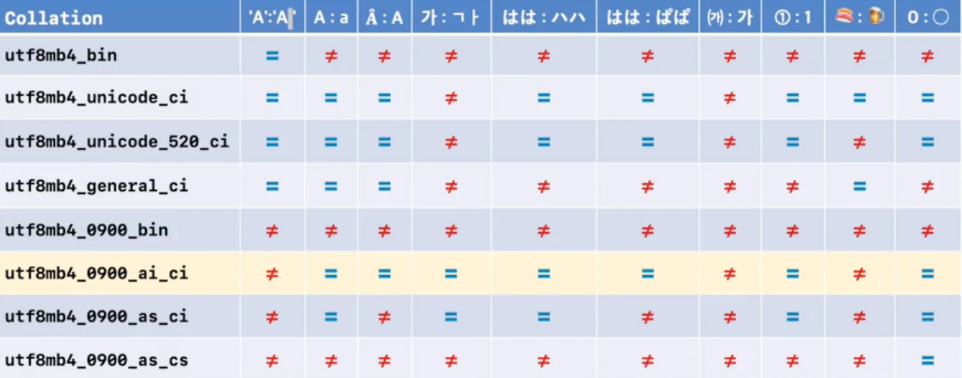
기본 콜레이션은 대소문자를 구분하지 않는다고 했는데, 그렇다면 어떤 콜레이션을 사용해야 될까요?
- 아래의 세 콜레이션 모두 대소문자를 구분하지만 동작하는 방식이 다릅니다. 각 특징을 살펴봅시다.
- utf8mb4_bin
- utf8mb4_0900_bin
- utf8mb4_0900_as_cs

즉 대소문자 구분을 위한 콜레이션 선정 기준은 다음과 같습니다.
- 후행 공백 인식을 원하지 않는 경우 (즉, 'a'와 'a'를 동일한 문자열이라고 판단하길 원함) → utf8mb4_bin 사용
- 후행 공백 인식을 원하거나 특별히 상관이 없으면서:
- 단순히 대소문자가 잘 구분되는 정도면 충분 → utf8mb4_0900_as_cs 사용
- 모든 문자를 명확하게 구분하고 싶은 경우 → utf8mb4_0900_bin 사용
'Backend > DB' 카테고리의 다른 글
| 풀스캔 쿼리 패턴 및 튜닝 (0) | 2024.12.26 |
|---|---|
| PK로 UUID 사용 시 주의사항 (2) | 2024.12.26 |
| Prepared Statement (3) | 2024.12.26 |
| LEFT JOIN 주의사항 & 튜닝 (0) | 2024.12.26 |
| 에러 핸들링 (2) | 2024.12.26 |