

1. 들어가며
PK를 고르는 것은 생각보다 까다로운 일입니다. 테이블 스키마의 가장 기본이 되는 값이면서도 그 영향 범위가 매우 넓기 때문인데요. Uniqueness를 생각해서 그냥 UUID를 사용하는 경우도 꽤 자주 본 것 같습니다. 오늘은 UUID를 PK로 사용할 때 주의할 점을 함께 살펴보겠습니다
2. UUID
정의
UUID는 'Universally Unique Identifier'의 약자로 128-bit의 고유 식별자입니다. 다른 고유 ID 생성 방법과 다르게 UUID는 중앙 시스템에 등록하고 발급하는 과정이 없어서 상대적으로 더 빠르고 간단하게 만들 수 있다는 장점이 있습니다.
하지만 완전히 고유하지 않을 확률이 있는데요. RFC 4122 문서에 정의된 UUID 버전 4 표준 규약을 따르면 1조 개의 UUID 중에 중복이 일어날 확률은 10억 분의 1이라고 합니다.
조금 더 자세한 정의는 다음 글을 참조해주세요!
https://docs.tosspayments.com/resources/glossary/uuid
UUID 포맷
- 일반적으로 5개의 파트로 나뉜 파트라고 정의합니다.

- 타임스탬프가 uuid의 여러 파트로 나뉘어 배치되기 때문에 정렬 순서가 일치하지 않습니다. 이는 pk 선정에 있어 꽤 중요한 요소인데 추후 살펴보겠습니다.
- uuid는 버전과 관계 없이 시점과 상관 없는 랜덤한 값을 만듭니다. (그나마 version-1이 가까운데 아닌 걸 위에서 확인했습니다.)
- 따라서 b-tree index 성능을 저해하는 요소가 있습니다. b-tree의 경우 길이가 짧고 단조적으로 증가할 때 효과적으로 동작합니다.
- 인덱스의 변경은 change buf로 빠르게 일어날 수 있는 것이 mysql의 장점인데 unique 제약이 걸려 있으면 change buf를 사용할 수 없습니다.
- 그래서 성능에 악영향을 미칠 수 있습니다.
- 길이가 길기 때문에 또한 pk로 사용 시 모든 secondary index에 악영향을 끼칠 수 있습니다.
UUID 사용이 성능에 악영향을 미친다니 무슨 이야기일까요? 이는 Index Working Set을 살펴보며 알아보겠습니다.
Index Working SET
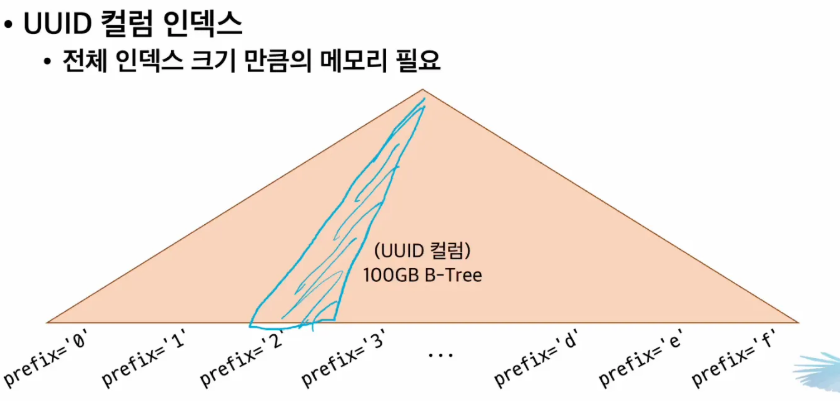
- mySQL의 index는 크기가 클 수도 있고 아닐 수도 있습니다.
- 크더라고 하더라도 mySQL은 꼭 필요한 부분만 읽어서 인덱스를 사용할 수 있게 되어 있습니다.
- 예를 들어 위와 같은 인덱스 모양이라고 하면 prefix = 2 라면 파란 부분만 읽으면 될 것입니다.
- 위와 같은 파란 부분을 index working set이라고 합니다.
- 그래서 index working set의 범위가 커질수록 디스크 IO가 늘어나게 됩니다.
- UUID 값은 어떤 버전을 사용하더라도 시간에 관계 없이 랜덤에 길이가 깁니다.
- 보통 데이터는 최근 데이터 조회가 많은 경우가 대부분입니다.
- 근데 UUID는 그러한 성질이 없습니다. 즉 생성 시간과 관계 없이 모든 범위를 가질 수 있습니다.
- 그래서 UUID 컬럼을 사용하면 모든 인덱스가 working set이 될 확률이 높습니다.
- 그래서 MySQL 서버에서는 UUID_TO_BIN 함수나 BIN_TO_UUID와 같은 함수를 지원합니다. swap flag를 1로 설정하면 시간 순서대로 정렬된 UUID를 반환해줍니다.

UUID의 길이 문제 - BIGINT와의 비교
UUID: 32자 (VARCHAR), 16바이트 (BINARY)
BIGINT: 8바이트
1억건 테이블 (10개 인덱스를 가진 테이블의 PK인 경우):
- 단일 인덱스 크기: 24GB vs 6GB
- 전체 인덱스 크기: 264GB vs 66GB
필요 인스턴스: - db.r5.12xlarge: total_mem=384GB (buffer_pool=277GB) $6,762
- db.r5.4xlarge: total_mem=128GB (buffer_pool=89GB) $2,254
4개 인스턴스 사용시 비용 차이: - $18,032/month = ₩22.54 천만/month
모든 secondary index는 Pk를 가지고 있어야 합니다. 그래야 클러스터링 인덱스에서 위치를 찾아서 갈 수 있습니다. 근데 aurora mysql은 보통 인스턴스 전체 메모리의 절반 정도만 InnoDB의 버퍼풀로 할당합니다. 데이터 자체도 innoDB 자체에 적재되어야 빠르다는 것을 생각하면 위의 인스턴스보다도 더 많이 드는 것입니다.
그럼 UUID의 대체제는 없을까요?
- 가장 간단한 것: DBMS에서 제공하는 autoincrement → 다음 Pk 값을 예측하기 쉬워진다는 단점이 있습니다.
- snowflake-uid
- sonyflake-uid: 위와 비슷한데 timestamp를 통해 생성하는데, 단조증가하는 값을 만드는 것입니다.
- timestamp based in house int64 uid
- timestamp prefix: 레인지 파티션을 위한 PK로 활용할 수 있습니다.
아니라면 대체키를 사용하며 내부적으로는 AutoIncrement 또는 TimeStamp 기반의 프라미어리키를 사용하고 외부적으로는 UUID 기반의 유니크 세컨더리 인덱스를 사용하는 방법도 있습니다.
CREATE TABLE table (
id BIGINT NOT NULL AUTO_INCREMENT,
external_uid CHAR(32) NOT NULL,
...
PRIMARY KEY (id),
UNIQUE INDEX ux_externaluid (external_uid)
);'Backend > DB' 카테고리의 다른 글
| COUNT 쿼리의 실행계획, 인덱싱 (0) | 2024.12.28 |
|---|---|
| 풀스캔 쿼리 패턴 및 튜닝 (0) | 2024.12.26 |
| 콜레이션 (Collation) - MySQL의 문자 비교 (0) | 2024.12.26 |
| Prepared Statement (3) | 2024.12.26 |
| LEFT JOIN 주의사항 & 튜닝 (0) | 2024.12.26 |